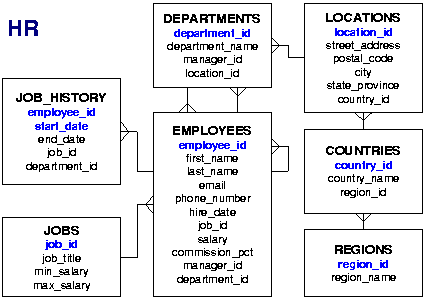
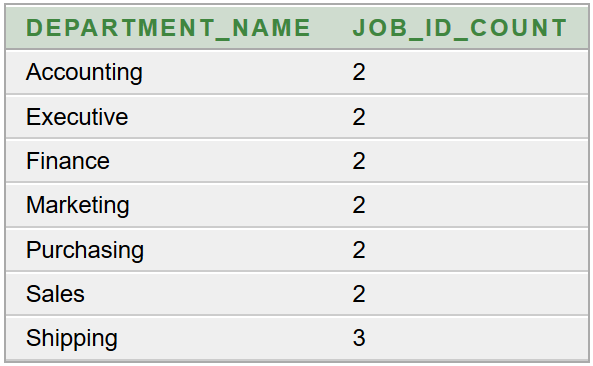
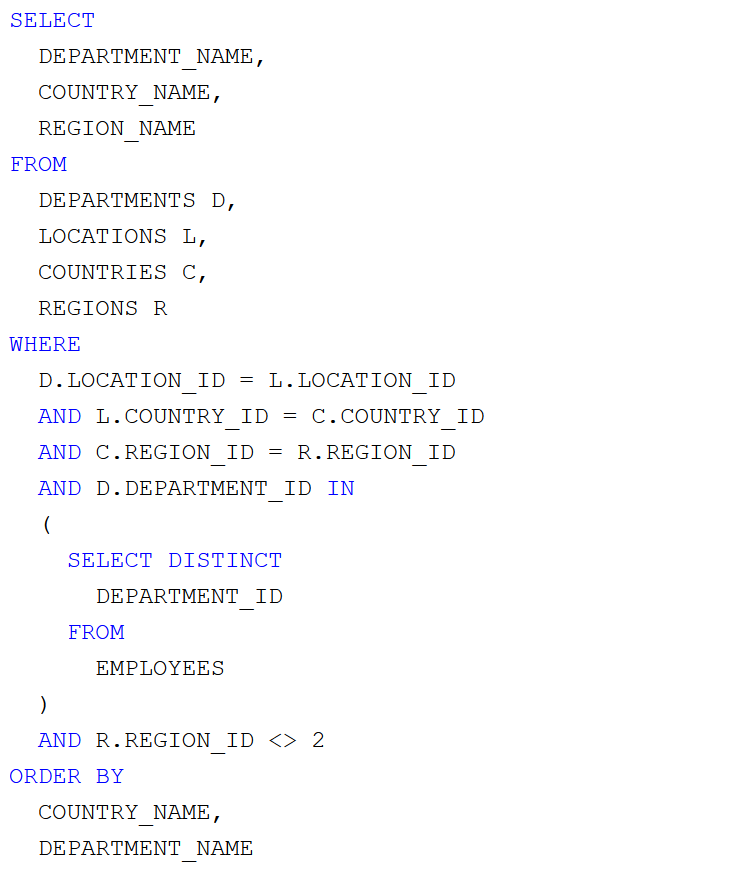
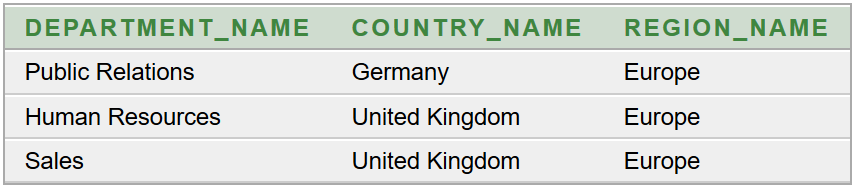
Az a feladatunk, hogy az Oracle HR sémából lekérdezve állítsuk elő a top 5 fizetésű alkalmazottak listáját, a fizetések csökkenő sorrendjében. Ez egytáblás lekérdezéssel megvalósítható. Az
EMPLOYEES táblában megtalálható az összefűzött névhez szükséges
FIRST_NAME és
LAST_NAME mezők, valamint a fizetés a
SALARY mezőben. Minden alkalmazottnak van neve és fizetése. Előfordul legalább 5 különböző fizetés.
Az a feladatunk, hogy az Oracle HR sémából lekérdezve állítsuk elő a top 5 fizetésű alkalmazottak listáját, a fizetések csökkenő sorrendjében. Ez egytáblás lekérdezéssel megvalósítható. Az
EMPLOYEES táblában megtalálható az összefűzött névhez szükséges
FIRST_NAME és
LAST_NAME mezők, valamint a fizetés a
SALARY mezőben. Minden alkalmazottnak van neve és fizetése. Előfordul legalább 5 különböző fizetés.
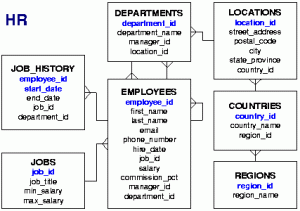
Tanfolyamainkon többféleképpen modellezzük és tervezzük meg a feladat megoldását.
Megoldás (Java SE szoftverfejlesztő tanfolyam)
A Java SE szoftverfejlesztő tanfolyam 45-52. óra: Adatbázis-kezelés JDBC alapon alkalmain a következők szerint modellezünk és tervezünk.
Kiindulunk az alábbi egyszerű lekérdező parancsból (V1):

Eredményül ezt kapjuk (részlet, V1):
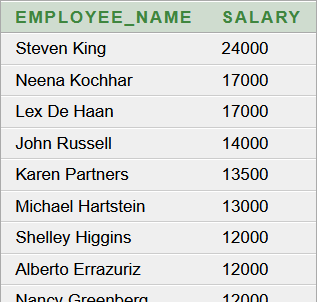
A kapott 107 rekordból álló eredménytáblát a Java kliensprogram fejlesztése során leképezzük egy generikus POJO listába, a rekordonként összetartozó két adatból előállítva az objektumok tulajdonságait. Kiderül, hogy a 17000 többször is előfordul. Mivel bármely fizetés előfordulhatna többször is, így előre nem tudjuk, hogy az eredménytáblából mennyi rekordot kell áttölteni a listába. A fizetésekből generikus halmazt építhetve, addig tudjuk folytatni a beolvasást, amíg a halmaz elemszáma kisebb ötnél. Eredményül hat rekordot kapunk. A Java kliensprogram forráskódját most nem részletezzük, de tanfolyamaink hallgatói számára ILIAS e-learning tananyagban tesszük elérhetővé a teljes forráskódot. Ennél a megoldásnál egyszerűbb a lekérdező parancs, de több feladat hárul a Java kliensprogramra.
Lássunk néhány tévutat és az általános megoldás helyett konkrét megoldásokat! Ha szeretnénk adatbázis oldalon megoldani a feladatot, akkor használhatnánk a
ROWNUM pszeudooszlopot. Ez 1-től sorszámozza az eredménytáblát, így használható lehetne arra, ha limitálni szeretnénk a visszaadandó rekordok számát.
1. elvi hibás lekérdező parancs:
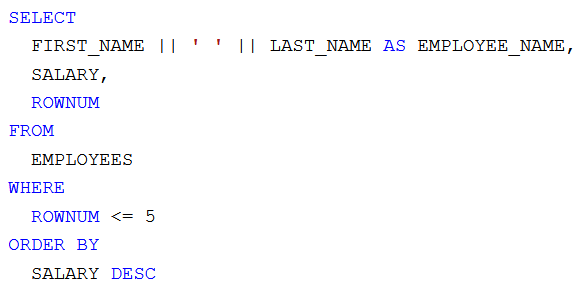
1. elvi hibás eredmény:
A hiba elvi, a lekérdező parancs szintaktikailag helyes. A harmadik oszlopban látjuk, hogy a rekordok sorszámozása megtörténik, de a kapott nevek és fizetések eltérnek a V1 esetben kapott helyes eredménytől. Az okokat természetesen megbeszéljük. Támpont: próbáljuk meg a lekérdező parancs feltételében kicserélni az 5-öt például 10-re és próbáljuk megmagyarázni, miért kapjuk azt, amit kapunk. Továbbá a konkrét esetben tudjuk, hogy hat rekordot kellene kapunk. Felmerülhet a gyanú, hogy a rendezés túl későn történik meg. Megpróbáljuk zárójelezéssel és lekérdezések egymásba ágyazásával befolyásolni a
WHERE és
ORDER BY alparancsok végrehajtási sorrendjét.
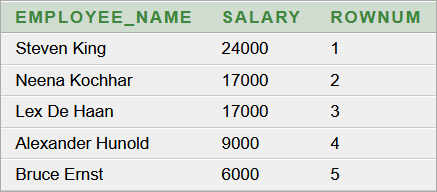
2. elvi hibás lekérdező parancs:

2. elvi hibás eredmény:
A hiba most is elvi, a lekérdező parancs szintaktikailag helyes. A zárójelezés valóban hatással van a két alparancs végrehajtási sorrendjére és megfigyelhető, hogy a harmadik oszlopban a rekordok táblabeli fizikai sorrendje jelenik meg és a feltétel (
ROWNUM <= 5) nem a mező értékére, hanem a rekordok darabszámára értendő. Nyilván az 5-öt 6-ra módosítva visszakaphatnánk a V1 első hat rekordját, de ez nem lenne általános megoldás. Más úton is eljuthatunk a konkrét megoldáshoz.
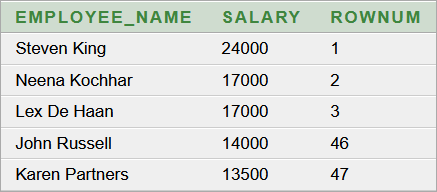
3. elvi hibás lekérdező parancs:
3. konkrét megközelítéssel kapott helyesnek látszó eredmény:
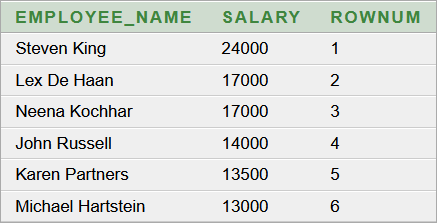
A hiba most is elvi, a lekérdező parancs szintaktikailag helyes. Általános megoldás helyett konkrét megoldásként megkapjuk a V1 első hat rekordját, de ehhez be kellett építeni a lekérdező parancsba a 13000-et. Ez a Top 5-ben legkisebb fizetés. Megbeszéljük, hogy miért hasznos a
DISTINCT módosító/kulcsszó beépítése a lekérdező parancsba.
Megoldás (Java adatbázis-kezelő tanfolyam)
A Java adatbázis-kezelő tanfolyam 9-12. óra: Oracle HR séma elemzése, 13-16. óra: Konzolos kliensalkalmazás fejlesztése JDBC alapon, 1. rész, 33-36. óra: Grafikus kliensalkalmazás fejlesztése JDBC alapon, 2. rész alkalmával a következők szerint modellezünk és tervezünk.
Most arra helyezzük a hangsúlyt, hogy back-end, azaz adatbázis oldalon állítsuk elő az eredményt és ezáltal a front-end, azaz a Java kliensprogram egyszerűbb lehet. A lekérdező parancsot belülről kifelé haladva gondoljuk végig. Először kell egy halmaz a különböző fizetésekről csökkenő sorrendben. Utána ebből kell az első öt darab, amelyek halmazt alkotnak. Végül erre építve kell azoknak az alkalmazottaknak a neve és fizetése, akiknek a fizetése benne van a halmazban.
1. majdnem helyes megoldás:

1. általános megközelítéssel kapott helyesnek látszó eredmény:
A probléma az, hogy az adatok helyes sorrendje a véletlennek köszönhető. Ha a lekérdező parancs feltételében az 5 helyett nagyobb számokat helyettesítünk be, akkor ez jól megfigyelhető. A következő megoldás már ezt a problémát is kezeli.
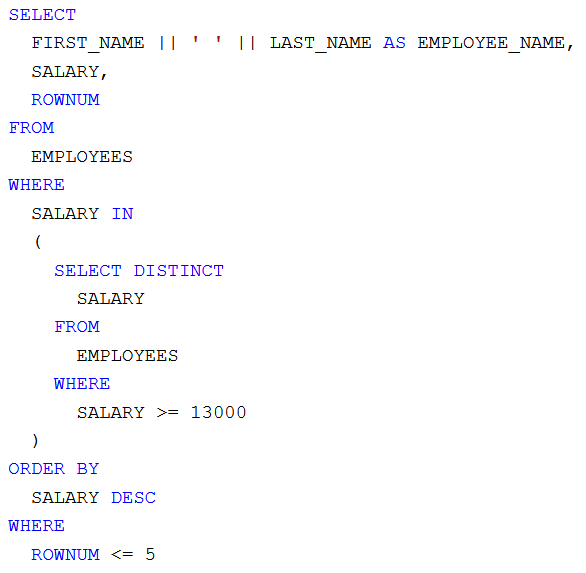
Finomítva a 3. elvi hibás lekérdező parancsot, a konkrét 13000 helyettesíthető belső lekérdező paranccsal. Építsük ezt be az 1. helyes megoldásba úgy, hogy az
IN predikátum helyett használjuk a nagyobb vagy egyenlő hasonlító operátort. A középső lekérdező parancs a halmaz helyett már csak egyetlen értéket adjon vissza, amelyhez könnyű hasonlítani az aktuális alkalmazott fizetését. Ezzel kiváltható a nagyobb memóriaigényű halmazban való tartalmazottságot eldöntő művelet, a jóval hatékonyabb egy értékkel való összehasonlítással. Memóriaigény szempontjából nem maga a konkrét művelet/operátor az érdekes, hanem a használatukhoz szükséges adatok előállítása, mennyisége, tárolása, feldolgozása.
2. helyes megoldás:

2. általános megközelítéssel kapott helyes eredmény:
Közben az is kiderült, hogy miért szükséges két helyen az
ORDER BY alparancs.
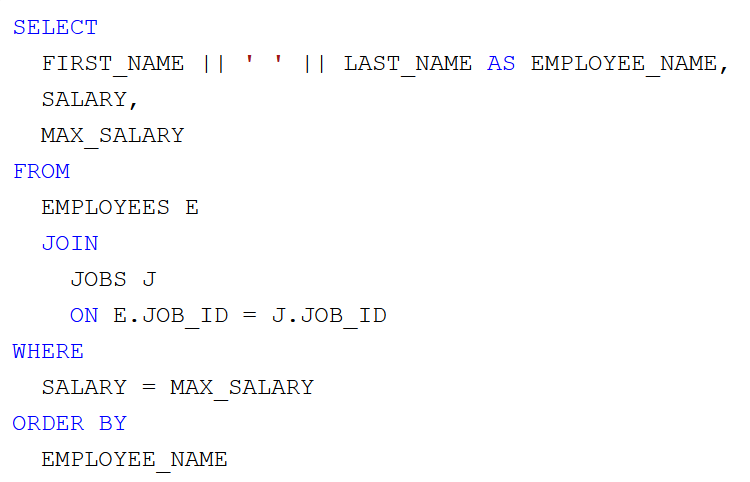
Végül, ha ismerjük az Oracle
DENSE_RANK() analitikai függvényét, amely egy rendezett lista különböző elemeihez rendel sorrendben számokat (másképpen rangsort állít fel 1-től kezdve), akkor elkészíthetjük az alábbi megoldást.
3. helyes megoldás:

3. általános megközelítéssel kapott helyes eredmény:
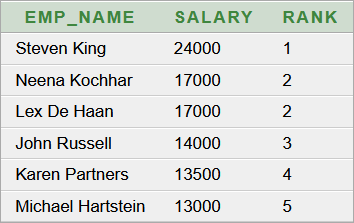
Érdemes átgondolni és összehasonlítani a többféle különböző megközelítés lehetőségeit, korlátait. Ha egyensúlyozni kell a kliensprogram és az adatbázis-szerver terhelése között, valamint az MVC modell összetettsége, karbantarthatósága, könnyen dokumentálhatósága a/is szempont, akkor többféle alternatív módszer is bevethető, valamint építhetünk a különböző Oracle verziók (dialektusok) képességeire is.
Az SQL forráskódok formázásához a Free Online SQL Formatter-t használtam.





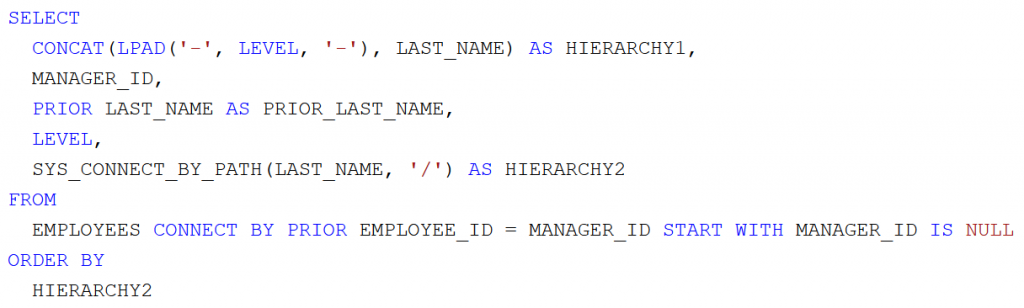
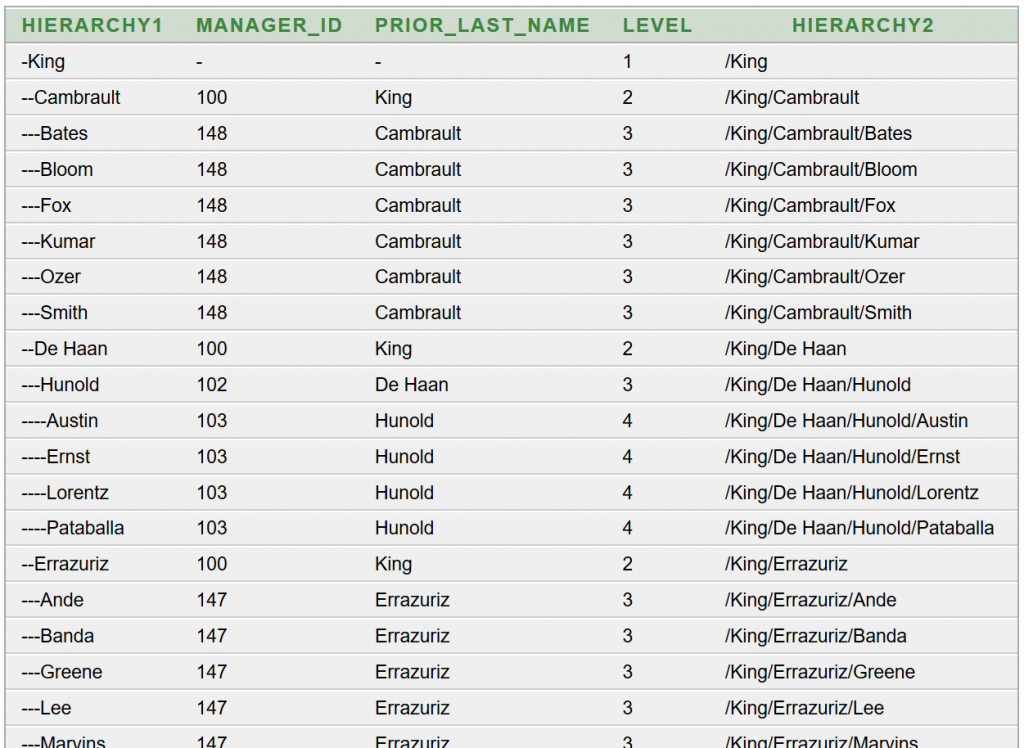
 Az SQL lekérdezések újabb típusát adják a hierarchikus lekérdezések. Az Oracle adatbázis-szerver már régóta támogatja ezt a lehetőséget. A hierarchia legtöbbször valamilyen fa adatszerkezethez kötődik. Ezek természetesen nem közvetlenül tárolódnak egy normalizált, relációs adatbázisban, de az adatok közötti kapcsolat értelmezése során felépíthető rekurzív módon a fa struktúra.
Az SQL lekérdezések újabb típusát adják a hierarchikus lekérdezések. Az Oracle adatbázis-szerver már régóta támogatja ezt a lehetőséget. A hierarchia legtöbbször valamilyen fa adatszerkezethez kötődik. Ezek természetesen nem közvetlenül tárolódnak egy normalizált, relációs adatbázisban, de az adatok közötti kapcsolat értelmezése során felépíthető rekurzív módon a fa struktúra.