

 Az a feladatunk, hogy az Oracle HR sémából lekérdezve állítsuk elő munkakörönként csoportosítva az alkalmazottak létszámát és névsorát. Adott a
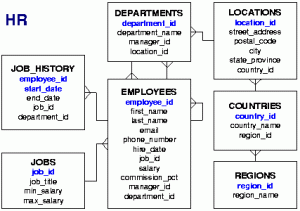
JOBS és az
EMPLOYEES táblák közötti 1:N kapcsolat. A
JOBS táblában (szótár) lévő
JOB_ID egyedi kulcshoz tartozik egy hosszabb szöveges
JOB_TITLE leírás (munkakör), valamint az
EMPLOYEES táblában megtalálható a
JOB_ID külső kulcsként. Az
EMPLOYEES táblában elérhető az alkalmazottak neve:
FIRST_NAME és
LAST_NAME. Minden munkakört betölt legalább 1 alkalmazott és minden alkalmazotthoz van hozzárendelt munkakör.
Az a feladatunk, hogy az Oracle HR sémából lekérdezve állítsuk elő munkakörönként csoportosítva az alkalmazottak létszámát és névsorát. Adott a
JOBS és az
EMPLOYEES táblák közötti 1:N kapcsolat. A
JOBS táblában (szótár) lévő
JOB_ID egyedi kulcshoz tartozik egy hosszabb szöveges
JOB_TITLE leírás (munkakör), valamint az
EMPLOYEES táblában megtalálható a
JOB_ID külső kulcsként. Az
EMPLOYEES táblában elérhető az alkalmazottak neve:
FIRST_NAME és
LAST_NAME. Minden munkakört betölt legalább 1 alkalmazott és minden alkalmazotthoz van hozzárendelt munkakör.
Tanfolyamainkon többféleképpen modellezzük és tervezzük meg a feladat megoldását.
Megoldás (Java SE szoftverfejlesztő tanfolyam)
A Java SE szoftverfejlesztő tanfolyam 45-52. óra: Adatbázis-kezelés JDBC alapon alkalmain a következők szerint modellezünk és tervezünk.
Kiindulunk az alábbi egyszerű SQL parancsból:

Eredményül ezt kapjuk (részlet):
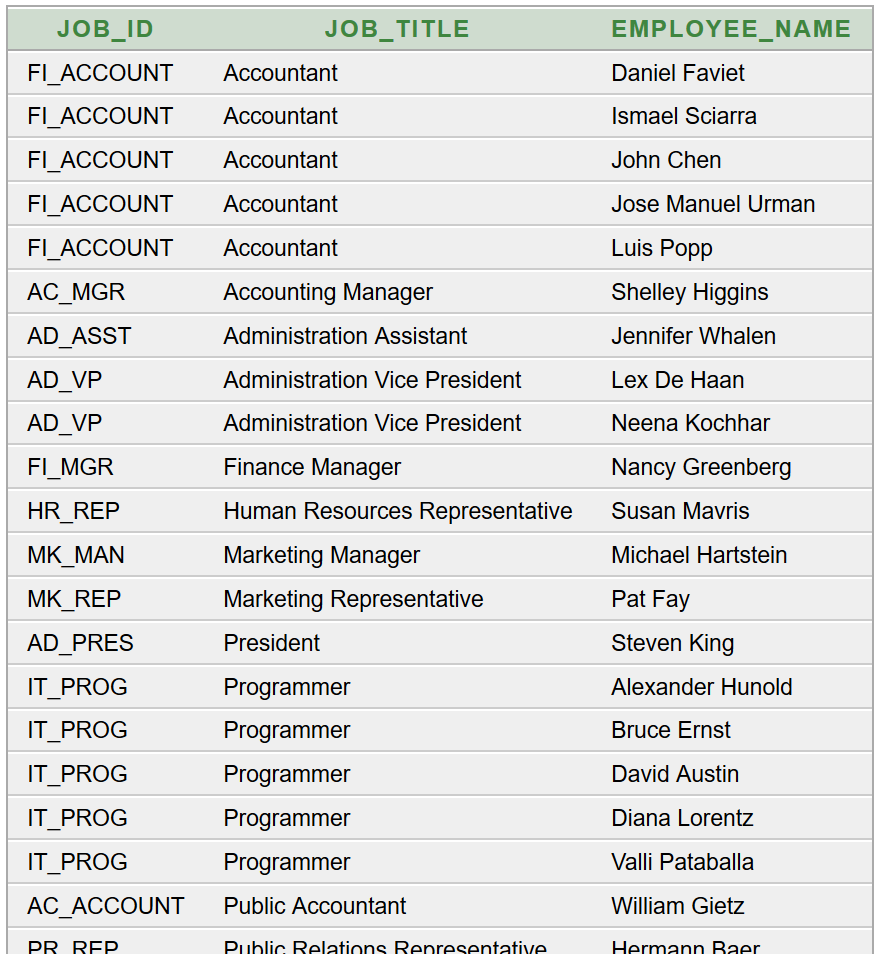
A kapott eredménytáblát a Java kliensprogram fejlesztése során leképezzük egy generikus POJO listába, a rekordonként összetartozó 3 adatból előállítva az objektumok tulajdonságait. A generikus listát csoportváltás algoritmussal feldolgozva, könnyen listázzuk a létszámot és a névsort munkakörönként csoportosítva. A munkakörönkénti létszámot a listafeldolgozás során megkapjuk. Ezt most nem részletezzük, de tanfolyamaink hallgatói számára ILIAS e-learning tananyagban tesszük elérhetővé a teljes forráskódot. Ennél a megoldásnál egyszerűbb a lekérdező parancs, de összetett az eredmény feldolgozása.
Megoldás (Java adatbázis-kezelő tanfolyam)
A Java adatbázis-kezelő tanfolyam 9-12. óra: Oracle HR séma elemzése, 13-16. óra: Konzolos kliensalkalmazás fejlesztése JDBC alapon, 1. rész, 33-36. óra: Grafikus kliensalkalmazás fejlesztése JDBC alapon, 2. rész alkalmával a következők szerint modellezünk és tervezünk.
Denormalizált eredményt közvetlenül visszaadni képes összetett SQL parancsot készítünk:

Eredményül ezt kapjuk (részlet):
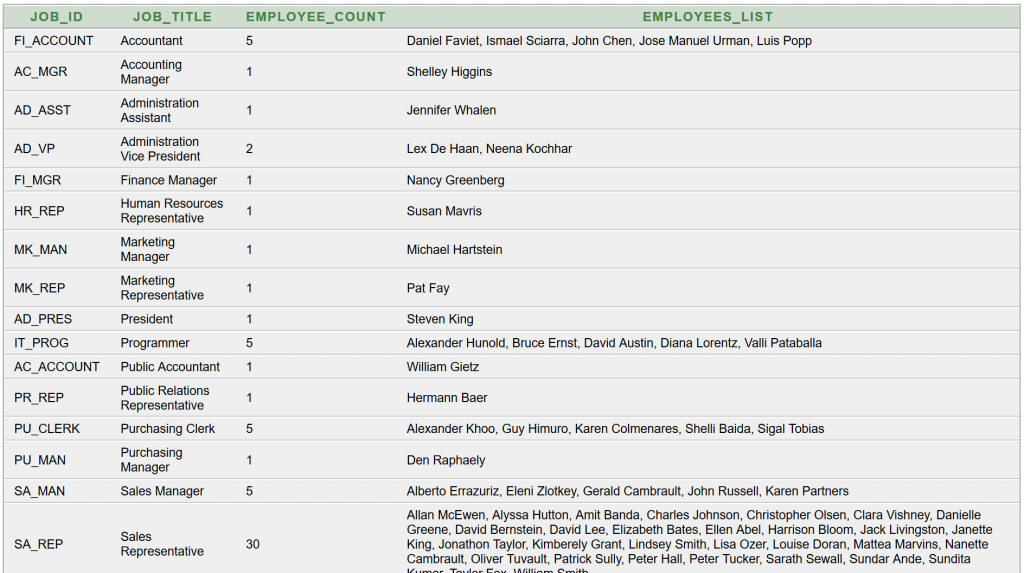
A kapott eredménytáblát a Java kliensprogram fejlesztése során közvetlenül kiíratjuk, hiszen minden szükséges adatot tartalmaz. Az utolsó oszlopban összefűzve megkapjuk az adott részleghez tartozó alkalmazottak névsorát. Ezt most nem részletezzük, de tanfolyamaink hallgatói számára ILIAS e-learning tananyagban tesszük elérhetővé a teljes forráskódot. Ennél a megoldásnál összetettebb a lekérdező parancs, de egyszerű az eredmény feldolgozása.
Érdemes átgondolni és összehasonlítani a kétféle különböző megközelítés lehetőségeit, korlátait. Ha egyensúlyozni kell a kliensprogram és az adatbázis-szerver terhelése között, valamint az MVC modell összetettsége, karbantarthatósága, könnyen dokumentálhatósága a/is szempont, akkor többféle alternatív módszer is bevethető, valamint építhetünk a különböző Oracle verziók (dialektusok) képességeire is.
Az SQL forráskódok formázásához a Free Online SQL Formatter-t használtam.

Ha jól értem, akkor attól denormalizált az eredmény, hogy az EMPLOYEES_LIST oszlopban egynél több adat is lehet?
Péter: igen, jóra gondolsz, de ketté kell választani. Szemantikailag (logikai, tartalmi szempontból) a névsor állhat több – összefűzött – névből is, de ez szintaktikailag (fizikai, formai szempontól) mindössze egyetlen szöveges adat az eredménytáblában munkakörönként (rekordonként).
Kösz Péter, oké.
A projektfeladatot továbbfejlesztettük Alkalmazottak életpálya modellje címmel, két részben:
A fenti lekérdezésekre építve, a projekt továbbfejlesztéseként, a kapott adatokból PDF fájlt készítünk.