Kiss Balázs kolléga Alkalmazottak életpálya modellje – munkakör, fizetés jutalék blog bejegyzése inspirálta ezt a blog bejegyzést. Az Oracle HR sémában az értékesítési vezetők adható havi fizetése 10000 és 20000 között van, átlagfizetésük 12200. Az üzletkötők paraméterei hasonlóan: 6000, 12000, 8350. A pénznem USD. Mi lenne, ha…? Ha többféleképpen is kalkulálhatnánk jutalékokat fizetési modellek alapján. Vajon hogyan lehetne választani? Következzen kétféle fizetési modell az alkalmazottak jutalékaihoz kötődően.
Alkossunk egy fizetési modellt! Hogyan kalkuláljuk a jutalékokat?
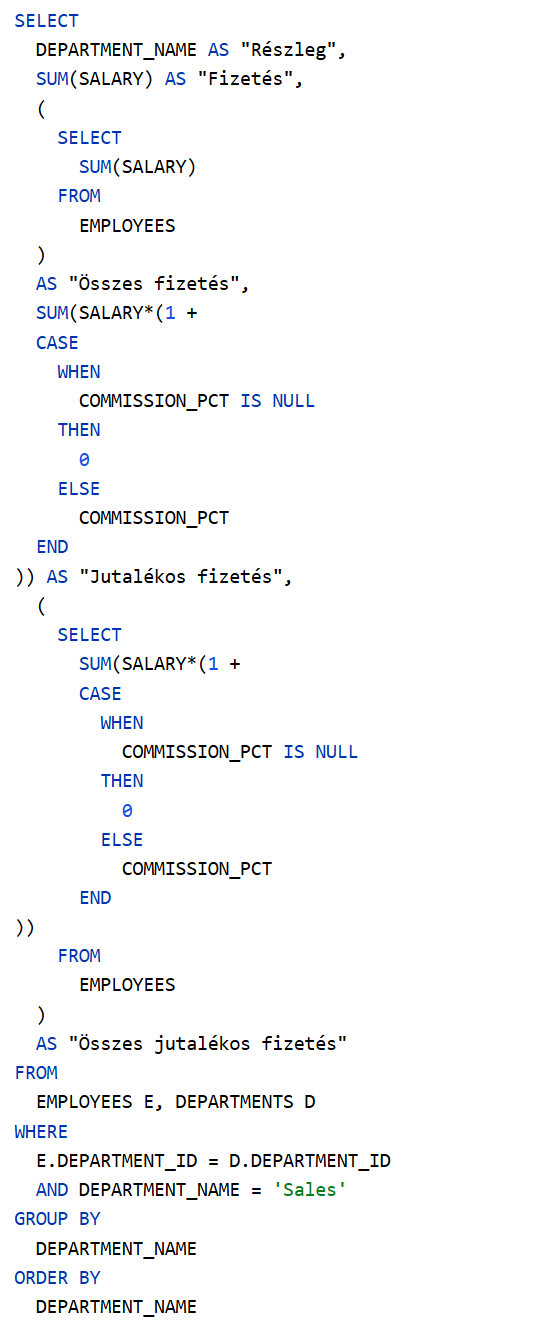
A jutalék negyedévente kerül kifizetésre és a havi fizetés megadott százaléka. Például: Elizabeth Bates üzletkötő havi fizetése 7300, jutaléka 15%, azaz minden 3. hónapban a fizetése 8395 helyett 10585. A negyedévek első két hónapjában a cég bérköltsége 691400, az utolsó hónapjában pedig 765090. Mindez arra a 106 fő alkalmazottra vonatkozik, akik részleghez tartoznak. Nincs benne az az 1 fő, aki nincs részleghez rendelve.
Összesített megoldás
A lekérdező SQL parancs:
Eredményül ezt az eredménytáblát adja:
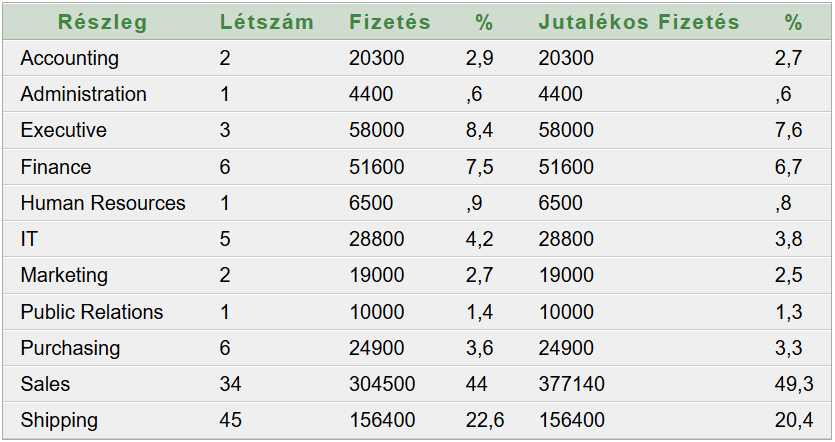
Részlegekre összesített 1. megoldás
Vegyük figyelembe azt a 106 fő alkalmazottat, akik részleghez tartoznak (a 107 fő közül). Az alábbi lekérdező SQL parancsot futtatva:
Az eredménytábla 11 rekordból áll. A százalékok a részlegre jutó bérköltség arányát fejezik ki (tényleges fizetésre és jutalékos fizetésre vonatkoztatva).
Részlegekre összesített 2. megoldás
Balázs írta, hogy a
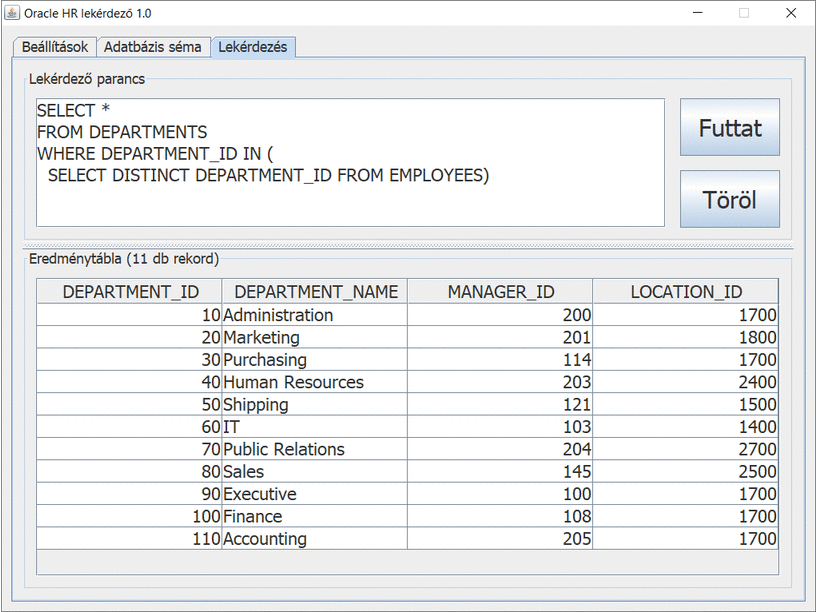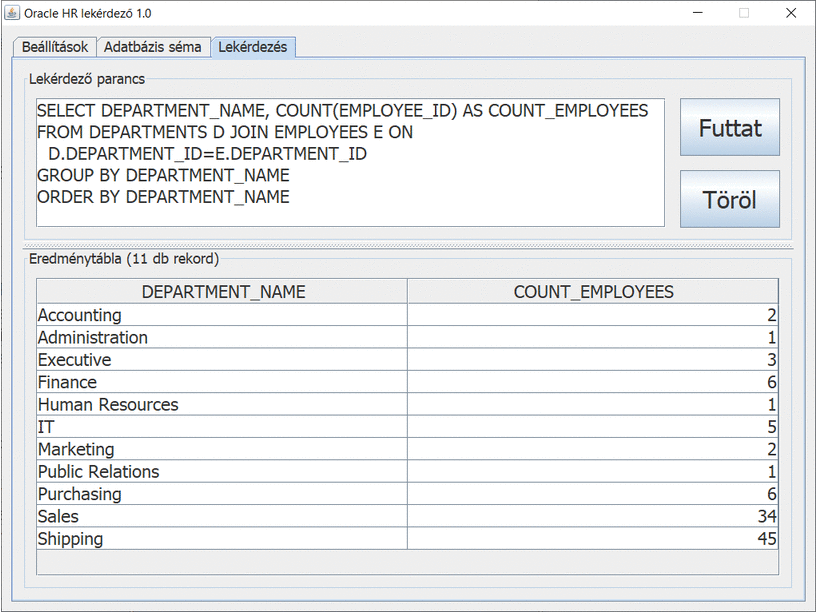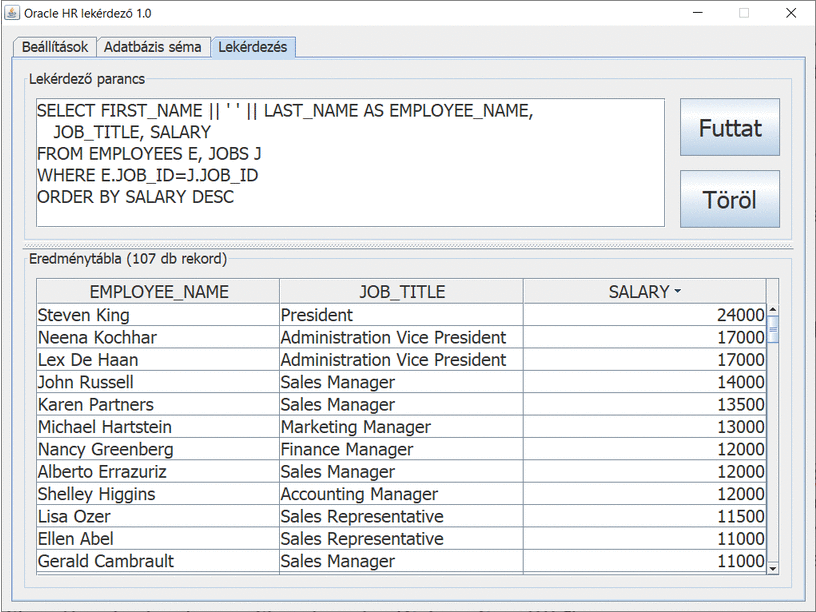
Sales részlegben 35-en dolgoznak. Ez akkor helytálló, ha a munkakörök alapján kérdezzük le és láttuk, hogy a 35 főből értékesítési vezetőként 5 fő, üzletkötőként 30 fő dolgozik. Igen ám, de van egy olyan alkalmazott, aki nem tartozik egy részleghez sem (
DEPARTMENT_ID IS NULL), ezért kapjuk az előző eredménytábla szerint a
Sales részlegben a 34 főt. Ugyanis az azt előállító lekérdező parancs a
DEPARTMENT_ID részlegazonosító alapján kapcsolja össze a két táblát (
EMPLOYEES és
DEPARTMENTS). Ha az ő fizetését is figyelembe kell venni, akkor ez lehetséges az alábbi lekérdező paranccsal:
Az eredménytáblában az utolsó, 12. rekord tartalmazza az eddig hiányzó 1 fő alkalmazott adatait:
Az eredménytábla – az utolsó rekord kivételével – majdnem megegyezik az előzővel. A fizetési modell szerint a negyedévek első két hónapjában a cégre vonatkozó bérköltség 7000-rel növekszik és a negyedévek harmadik hónapjában pedig 8050-nel. A fizetések arányát százalékban egy tizedesjeggyel ábrázolva szinte nem vehető észre a különbség. A rekordok azonos sorrendjétől tekintsünk most el, hiszen a
UNION és az
ORDER BY alparancsok alkalmazása együtt külön történet. Aki érti, hogy mire gondolok, most biztosan kacsint egyet. 😉 Aki még nem érti, annak részletesen elmagyarázzuk Java adatbázis-kezelő tanfolyamunkon. Továbbá a százalékokat összesítve a kerekítésük miatt nem kapunk pontosan 100%-ot.
Az így kapott adatok kiegészítik a Top 5 fizetésű alkalmazottak listája blog bejegyzésben kapott adatokat. Ott nem szerepelnek az alkalmazottak részlegei, de természetesen könnyen összepárosíthatók. Másképpen: a 107 fő alkalmazottból 35 fő (32,7%) kapja a fizetések 45%-át jutalék nélkül, illetve 50,4%-t jutalékkal kalkulálva. Tehát érdemes/megéri a
Sales részlegben dolgozni. Még akár jutalék nélkül is. 🙂
A bejegyzéshez tartozó teljes Java forráskódot (ami beépítve tartalmazza a fenti SQL lekérdező parancsokat) ILIAS e-learning tananyagban tesszük elérhetővé tanfolyamaink résztvevői számára.
A feladatok a Java adatbázis-kezelő tanfolyam 13-16. óra: Konzolos kliensalkalmazás fejlesztése JDBC alapon, 1. rész alkalmához és a 33-36. óra: Grafikus kliensalkalmazás fejlesztése JDBC alapon, 1. rész alkalmához kötődnek.
Alkossunk másik fizetési modellt! Várjuk hozzászólásban a megoldás SQL parancsait.
Vajon hogyan változna az előző fizetési modell, ha a negyedévente kifizetendő jutalék számítási alapja a havi fizetés helyett a háromhavi – időszakra vonatkozó – fizetés megadott százaléka lenne? Hogyan alakulna a cég bérköltsége?
Az Oracle HR sémában 11 részleg található 107 alkalmazottal, akik 19 különböző munkakörben végzik munkájukat. Nyilvánvalóan mindenkinek a fizetése pozitív (
SALARY>0), havi, USD pénznemben. Két munkakörre jellemző, hogy tartozik hozzá jutalék (
COMMISSION_PCT), amely pozitív valós szám. A 17 többi munkakörben foglalkoztatott alkalmazott esetében az adatbázis
EMPLOYEES táblájának jutalék mezőjében
NULL található. Az Oracle HS séma:
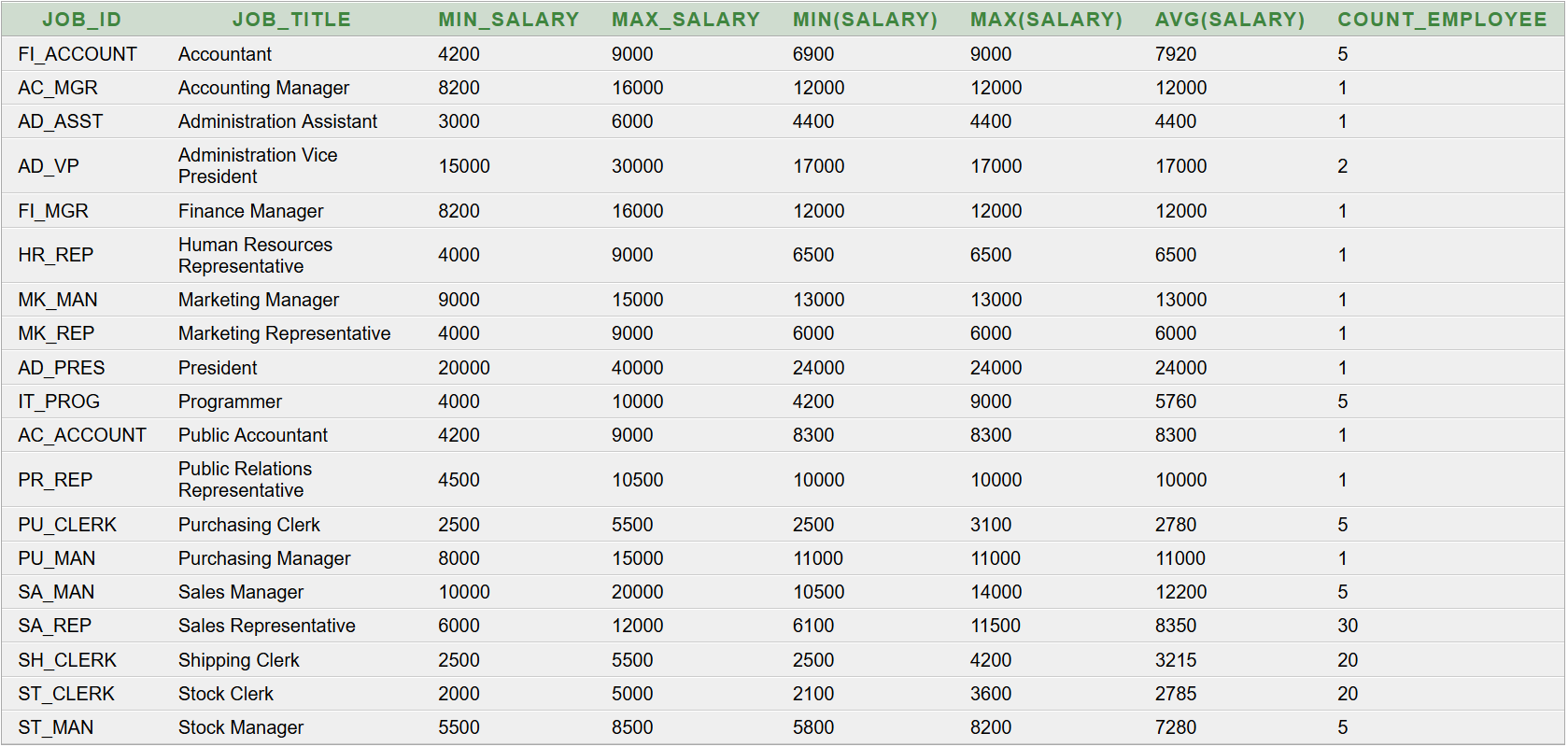
Életpálya-modellnek tekinthető a munkakörhöz (
JOB_ID és
JOB_TITLE) tartozó adható legkisebb és legnagyobb fizetés (
MIN_SALARY,
MAX_SALARY) nyújtotta mozgástér. Minden alkalmazottra teljesül, hogy a fizetése a megadott határok között található (zárt intervallumként kezelve). Ennek ellenőrzésére használható az alábbi SQL parancs:
Eredménytábla:
A
MIN(SALARY) oszlopban található a valós/kapott fizetések minimuma. A mellette lévő oszlopok hasonlóan a maximumot és az átlagot mutatják. A részlegben található alkalmazottak számát az utolsó,
COUNT_EMPLOYEE oszlop tartalmazza.
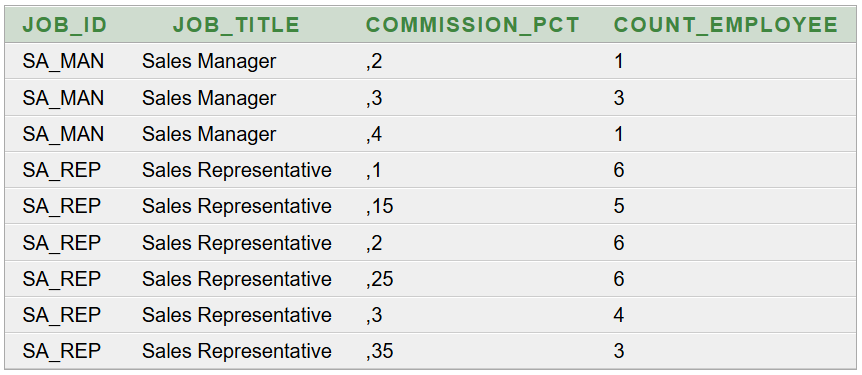
35 fő dolgozik a
Sales részlegben. Az 5 fő
Sales Manager (értékesítési vezető) jutaléka a fizetés 20%-ától 40%-áig terjedhet 10%-os lépésközzel (3-féle lehet). A 30 fő
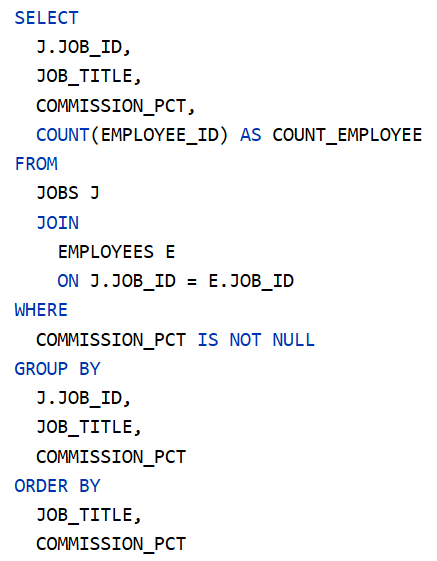
Sales Representative (üzletkötő) jutaléka a fizetés 10%-ától 35%-áig terjedhet 5%-os lépésközzel (6-féle lehet). Ennek igazolására használható az alábbi SQL parancs:
Eredménytábla:
A bejegyzéshez tartozó teljes Java forráskódot (ami beépítve tartalmazza a fenti SQL lekérdező parancsokat) ILIAS e-learning tananyagban tesszük elérhetővé tanfolyamaink résztvevői számára.
A feladatok megoldása során nem foglalkoztam külön azzal az egy alkalmazottal, akinek nincs részlege. A feladatok a Java adatbázis-kezelő tanfolyam 13-16. óra: Konzolos kliensalkalmazás fejlesztése JDBC alapon, 1. rész alkalmához és a 33-36. óra: Grafikus kliensalkalmazás fejlesztése JDBC alapon, 1. rész alkalmához kötődnek.
A Java programozási nyelv egyik ismert GUI csomagja a swing. Ennek népszerű grafikus komponense az adatok táblázatos megjelenítését biztosító
JTable komponens. A táblázatos megjelenítéshez több beállítás is szükséges. A
JTable egy MVC komponens, így külön kezelendők a modell, nézet és a vezérlő funkcióihoz kötődő beállítások. A modell tárolja az adatokat például
DefaultTableModel típusú objektumban, amiben szétválaszthatók a fejlécben és a többi cellákban található adatok. A nézethez tartozik a betűméret, a cellák színezése, az adatok igazítása, megjelenítése, a gördítősáv. A viselkedést, a felhasználói reakciót a vezérlő határozza meg, például rendezés, görgetés, fókusz, kijelölés, oszlopok sorrendjének cseréje.
Feladat
Készítsünk olyan Java swing-es kliensprogramot, amely tetszőleges adatforrásból (XML vagy JSON a hálózatról, JDBC adatbázis kapcsolatból, ORM leképzésből származó objektumokból) képes az átvett adatok grafikus felületen való táblázatos megjelenítésére
JTable komponenssel! Építsünk arra, hogy az adatokon kívül metaadatok is rendelkezésünkre állnak! A megoldás legyen univerzális!
Képernyőképek
Modell
A táblázatos GUI komponenst kezdetben inicializálni kell, illetve a benne tárolt adatok is törölhetők, ha újrahasznosításra kerül a sor:
1
2
JTable tbEredmeny=newJTable();
tbEredmeny.setModel(newDefaultTableModel());
Ki kell nyerni a tároláshoz és a megjelenítéshez kötődő adatokat (1. lépés). A metaadatokból a
for() ciklus előállítja az
oszlopTomb-öt, és az
oszlopTipusTomb-be kerülnek az Oracle adattípusból Java objektumtípusként megfeleltetett adatok. Előbbi a fejléc feliratainak szövegeit tartalmazza, és az utóbbi befolyásolja az egyes cellákban az igazítást, illetve hatással van adott oszlop rendezésére is:
Ki kell nyerni a tároláshoz és a megjelenítéshez kötődő adatokat (2. lépés). A
while() ciklus végigjárja az eredménytábla sorait és
Object típusú tömböt állít elő az összetartozó rekord mezőiből. Ezek először generikus listába kerülnek, majd onnan kétdimenziós
Object típusú tömbbe:
Mi indokolja a tömbökből álló generikus lista (
adatLista) alkalmazását?
A
while() ciklus végrehajtása előtt nem tudjuk lekérdezni, hogy mennyi rekordot kaptunk vissza, így nem tudjuk rögtön az
adatTomb-be tenni az adatokat. A Java nyelvben a tömbök mérete fix, és a deklaráció során meg kell adni. Az eredménytábla metaadatai között megtalálható a mezők száma, ami felhasználható a kétdimenziós tömb oszlopszámaként. A generikus lista dinamikus, annyi elemből fog állni, ahány lépésben végrehajtódik a
while() ciklus. Ezután a listától lekérdezhető az elemszáma (
adatLista.size()), és ezzel megvan a kétdimenziós tömb sorainak száma, ami eddig hiányzott. Persze használhatnánk
Vector-t is a tömbökből álló generikus lista helyett (mert a
DefaultTableModel-nek van olyan túlterhelt konstruktora, ami átvenné paraméterként), de ezt inkább nem tesszük, hiszen a
Vector már régóta obsolete kollekció.
Előállítjuk a vizuális komponens mögötti adatmodellt. Öröklődéssel kiegészítjük két hasznos függvénnyel, így cellák rajzolása/renderelése és rendezése megkaphatja a szükséges adattípust (
getColumnClass()), valamint letiltható a cellák szerkeszthetősége (
isCellEditable()). Utóbbiak inkább a vezérléshez kötődnek, de modellen keresztül itt és így kell beállítani:
Végül a vizuális komponens mögötti adatmodellt kell átadni:
1
tbEredmeny.setModel(dtm);
Nézet
Adott betűtípus, betűstílus és betűméret használható a táblázat fejlécében, celláiban, illetve a betűmérettől függhet a sorok magassága:
1
2
3
4
Font betutipus=newFont("Tahoma",Font.PLAIN,18);
tbEredmeny.getTableHeader().setFont(betutipus);
tbEredmeny.setFont(betutipus);
tbEredmeny.setRowHeight(24);
Hasznos ha
JScrollPane típusú gördítősáv tartozik a táblázathoz, így dinamikusan megjeleníthető/elrejthető a függőleges/vízszintes gördítősáv:
1
spGorditosav.setViewportView(tbEredmeny);
Vezérlés
Az adatokhoz valahogyan hozzá kell jutni. Most JDBC kapcsolatot használunk és az Oracle HR sémából kérdezünk le adatokat, de a forráskód-részlet univerzális. A folyamat a következő:
Betöltjük a
driver osztályt.
Autentikációval
c kapcsolatot nyitunk az adatbázis-szerver felé.
Végrehajtjuk a lekérdező SQL parancsot.
Feldolgozzuk az eredményül kapott
ResultSet típusú
rs objektumot.
Ha engedélyezzük, akkor a megjelenő táblázat fejlécében az egyes oszlopok felirataira kattintva elérhetjük, hogy az adott oszlop típusának megfelelően növekvő vagy csökkenő sorrendbe átrendeződjenek az adatok:
1
tbEredmeny.setAutoCreateRowSorter(true);
A kivételkezelést nem részleteztük a fenti forráskódoknál, de természetesen kötelezően adott.
A bejegyzéshez tartozó teljes forráskódot ILIAS e-learning tananyagban tesszük elérhetővé tanfolyamaink résztvevői számára.
Hasonlítsuk össze a részlegeket fókuszálva arra, hogy az alkalmazottak mennyire vettek korábban részt projektmunkákban! Hányan igen és hányan nem? Van(nak) olyan részleg(ek), amelyik vezetője egyetlen alkalmazottat sem vont be projektmunkába? Van(nak) olyan részleg(ek), ahonnan mindenki csatlakozott? Vannak a feladatkiosztásban olyan aránytalanságok, amelyek kimutathatók és így a későbbiek során korrigálhatók? Készítsünk egy kimutatást arról, hogy részlegenként hány fő vett részt projektmunkában és mi a létszám! (Persze tudjuk, hogy nem minden munkakörből vonhatók be alkalmazottak.) Milyen projektjeink szoktak lenni? Van olyan részleg, ahol érdemes bővíteni a létszámot, esetleg átcsoportosítani oda erőforrást? Ezekre a kérdésekre keressük a választ.
Tervezés
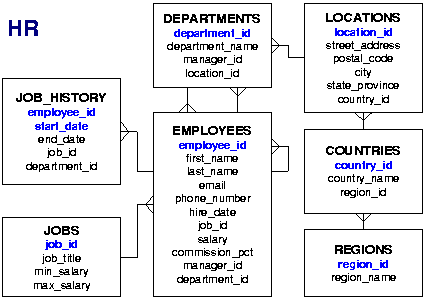
Az Oracle HR sémában három tábla kapcsolódik a feladathoz:
JOB_HISTORY,
EMPLOYEES,
DEPARTMENTS. A kapcsolatok fokszámai láthatók az alábbi ábrán. Egy részlegben több alkalmazott is lehet. Egy alkalmazott részt vehetett korábban több projektmunkában is.
A
DEPARTMENTS táblában található a részleg azonosítója (
DEPARTMENT_ID, kulcs) és neve (
DEPARTMENT_NAME). A többi adat most nem kell. 11 olyan részleg van, amihez tartozik alkalmazott.
A
JOB_HISTORY tábla tárolja, hogy a már befejeződött projektekben ki (
EMPLOYEE_ID, külső kulcs) és melyik részlegből (
DEPARTMENT_ID, külső kulcs) vett részt. A dátumokat (
START_DATE,
END_DATE) és a munkakör külső kulcsát (
JOB_ID) most nem használjuk. Minden projekt lezárt. 10 lezárt projekt van.
Az
EMPLOYEES táblából szükséges az alkalmazott azonosítója (
EMPLOYEE_ID, kulcs), valamint részlegének azonosítója (
DEPARTMENT_ID, külső kulcs). A többi adatra most nincs szükség, de egy részletesebb – például név szerinti – kimutatáshoz már igen. 106 olyan alkalmazott van, akihez tartozik részleg (1-nek nincs).
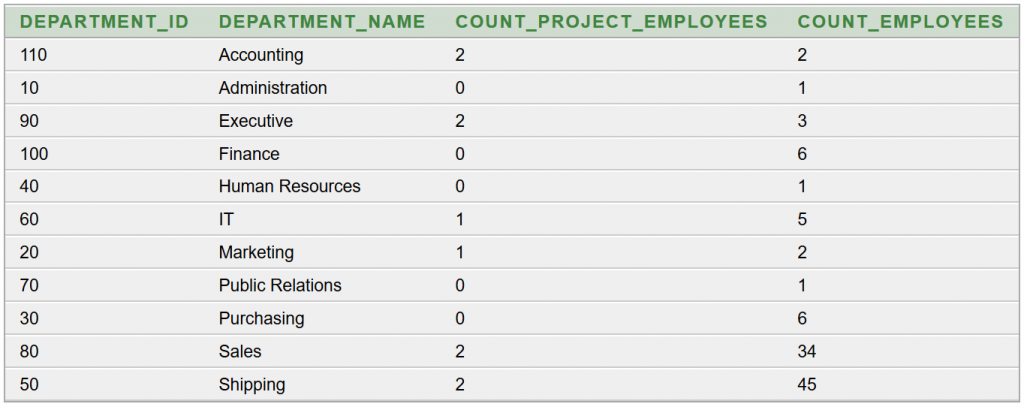
Hozzunk létre négy oszlopból álló eredménytáblát:
DEPARTMENT_ID,
DEPARTMENT_NAME,
COUNT_PROJECT_EMPLOYEES,
COUNT_EMPLOYEES. Ennek áttekintésével választ kaphatunk a fenti kérdésekre.
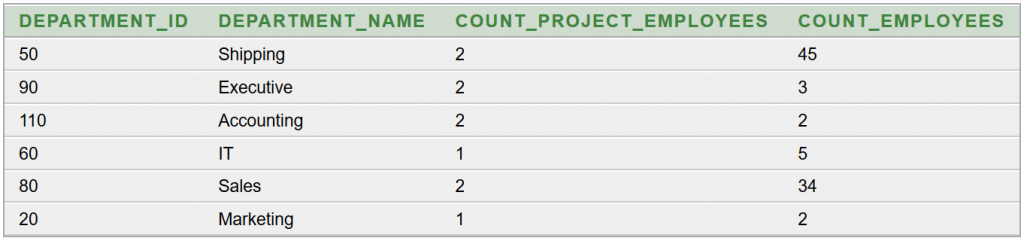
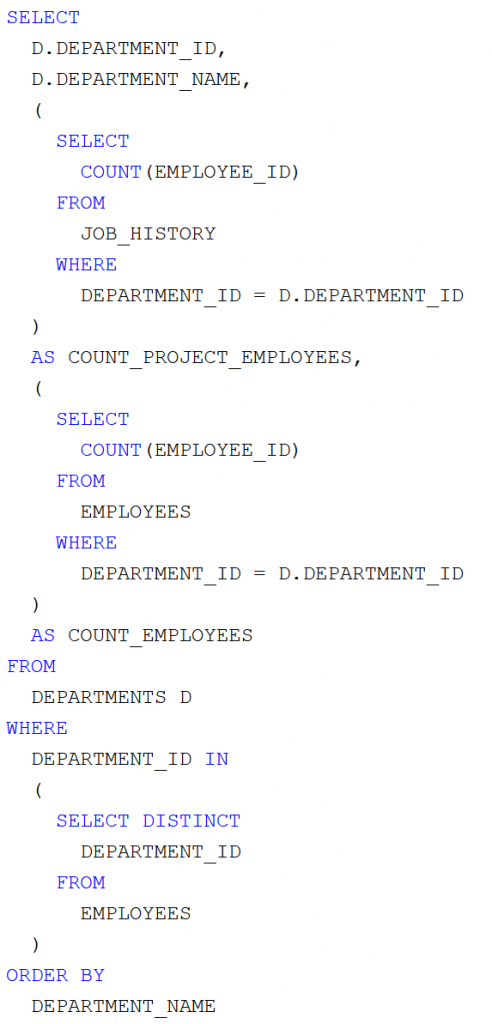
1. megoldás
Induljunk ki abból, hogy a
JOB_HISTORY táblában lévő
DEPARTMENT_ID-hez hozzárendeljük a
DEPARTMENTS táblából a
DEPARTMENT_NAME-t. Ezekre csoportosítva könnyen aggregálható az adott részlegből projektmunkát végző alkalmazottak száma:
COUNT_PROJECT_EMPLOYEES. Végül egy belső lekérdezés (összekapcsolva a
JOB_HISTORY és az
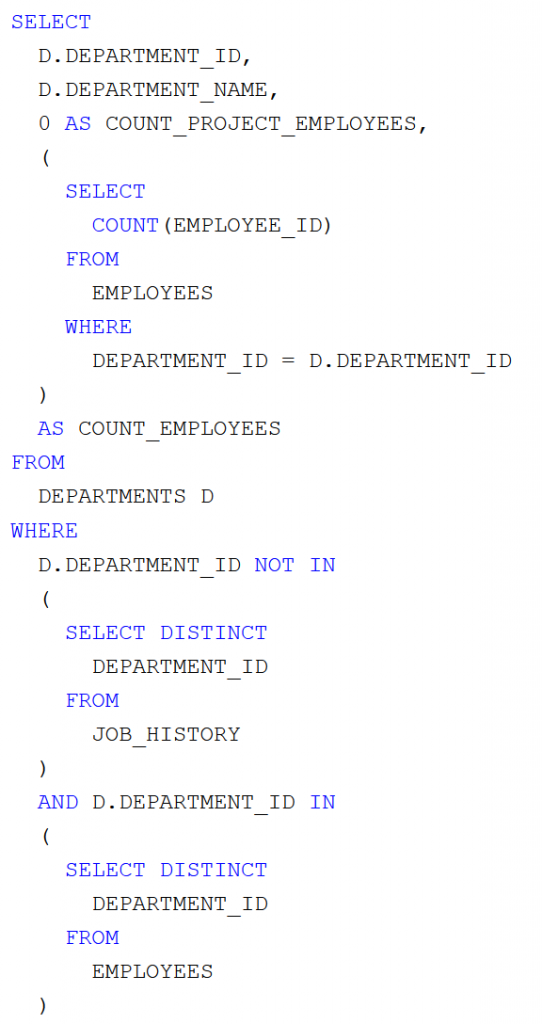
EMPLOYEES táblákat) megadja az adott részleg alkalmazotti létszámát. Az SQL lekérdezés:
A részeredmény:
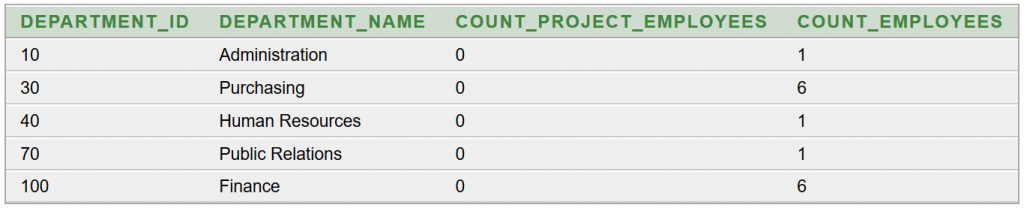
Ezután állítsuk elő a hiányzó adatokat! Tudjuk, hogy azokban a részlegekben, amelyek
DEPARTMENT_ID-je nem szerepel a
JOB_HISTORY táblában, de szerepel az
EMPLOYEES táblában, azok léteznek, de nem „adtak” projektmunkára alkalmazottat (azaz
COUNT_PROJECT_EMPLOYEES=0). Nevük és alkalmazottaik száma ugyanúgy megadható, ahogyan az előbb. Az SQL lekérdezés:
A részeredmény:
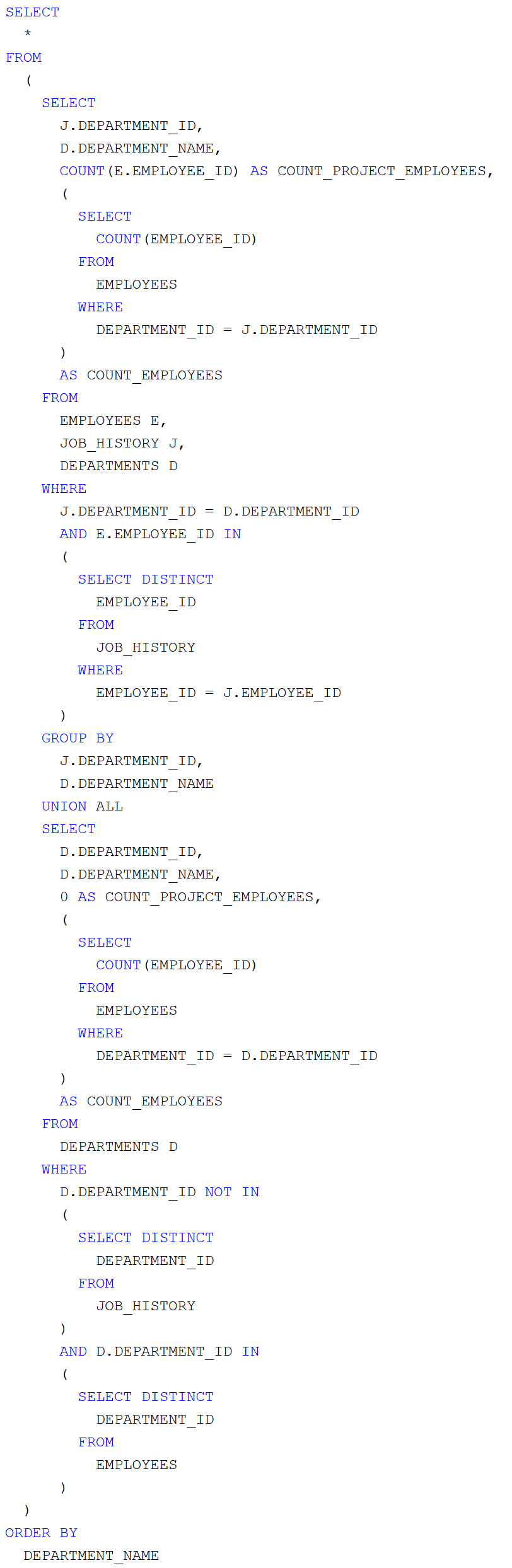
A két részeredményt egyesíteni kell és egyben hasznos
DEPARTMENT_NAME szerint növekvő sorrendbe rendezni az alábbi lekérdező paranccsal:
Az eredmény:
2. megoldás
Kiindulhatunk abból is, hogy a
DEPARTMENTS egy szótártábla, így közvetlenül hozzáférhető a
DEPARTMENT_ID és a
DEPARTMENT_NAME, de össze kell kapcsolni az
EMPLOYEES táblával, hogy csak olyan részlegeket adjon vissza a lekérdezés, ahol van(nak) alkalmazott(ak). Az eredményhez szükséges további két oszlop könnyen aggregálható az adott részlegre vonatkozóan: a
JOB_HISTORY táblában előforduló
EMPLOYEE_ID-k száma adja a
COUNT_PROJECT_EMPLOYEES-t (probléma nélkül tud 0 lenni) és az
EMPLOYEES táblában előforduló
EMPLOYEE_ID-k száma adja a
COUNT_EMPLOYEES-t. A rendezés most is szükséges. Lényegesen tömörebb lekérdező parancsot kapunk:
Az eredményül kapott táblázat megegyezik az 1. megoldás eredményével.
A két megoldás teljesen különböző gondolatmenettel született. Mindkettőben vannak olyan elemek, amelyek – konkrét feladatból általánosítva – univerzálisan használhatók. Természetesen összehasonlítjuk a két megoldás végrehajtási tervét és részletesen elemezzük is.
A bejegyzéshez tartozó teljes forráskódot ILIAS e-learning tananyagban tesszük elérhetővé tanfolyamaink résztvevői számára.
Az Oracle HR sémából építünk organogramot, amivel megjeleníthető a szervezeti hierarchia. Személyenként készítünk csomópontokat. (Másképpen is lehetne: például részlegenként.) A megvalósítás során kétszer konvertálunk A-ból B-be. Először az adatbázisból/adatforrásból SQL lekérdezéssel jutunk hozzá a szükséges adatokhoz, amelyeket generikus listába képezzük le. Ezután a listát feldolgozva generálunk HTML fájlt, amely tartalmaz egy Organization Chart diagramot.
Hasonló feladat: Ki kinek a vezetője?, rekurzív lekérdezéssel. Érdemes összehasonlítani a kétféle szemléletmódot.
Tervezés
Most pedig azt használjuk fel, hogy az Oracle HR sémában az
EMPLOYEES táblában reflexió van, amelyet az
EMPLOYEE_ID és a
MANAGER_ID mezők biztosítanak.
Az Organization Chartnál három adatsor adható meg. Ezek most testre szabva (mindegyik szöveges):
'Employee lastname',
'Job ID', valamint jelmagyarázatként további három mező összefűzve:
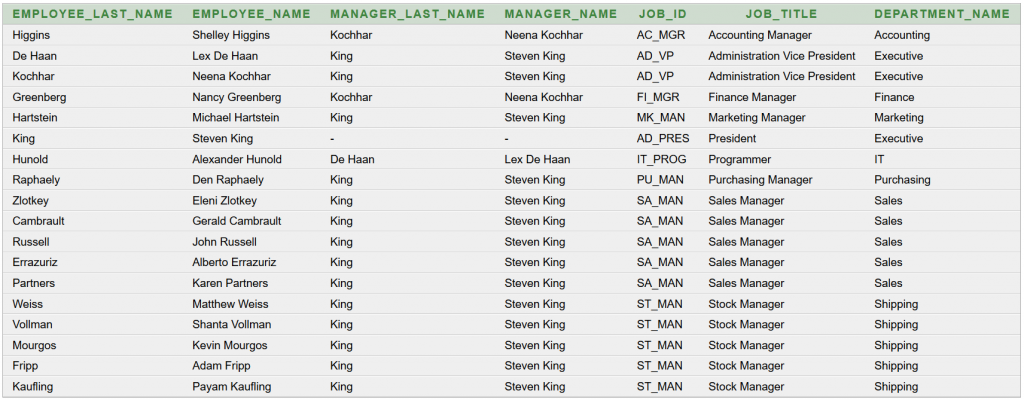
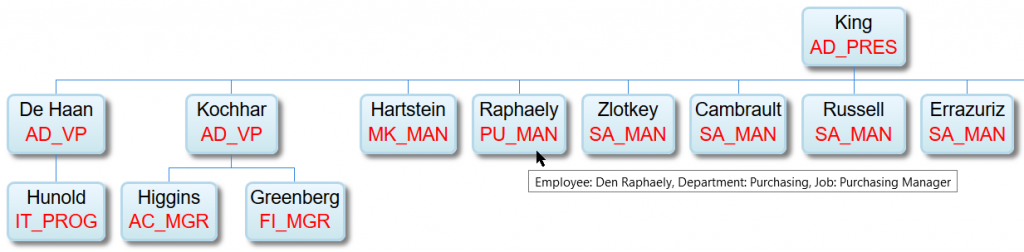
'Employee name, Department name, Job title'. Az organogramon megjelenő adatok például:
"Raphaely",
"PU_MAN", valamint a csomópontra fókuszálva megjelenő tooltip:
"Employee: Den Raphaely, Department: Purchasing, Job: Purchasing Manager". A
DEPARTMENTS táblából – az
EMPLOYEES-zel a
DEPARTMENT_ID-vel összekötve – megkapjuk a
DEPARTMENT_NAME-t. A
JOBS táblából pedig – az
EMPLOYEES-zel a
JOB_ID-vel összekötve – megkapjuk a
JOB_TITLE-t.
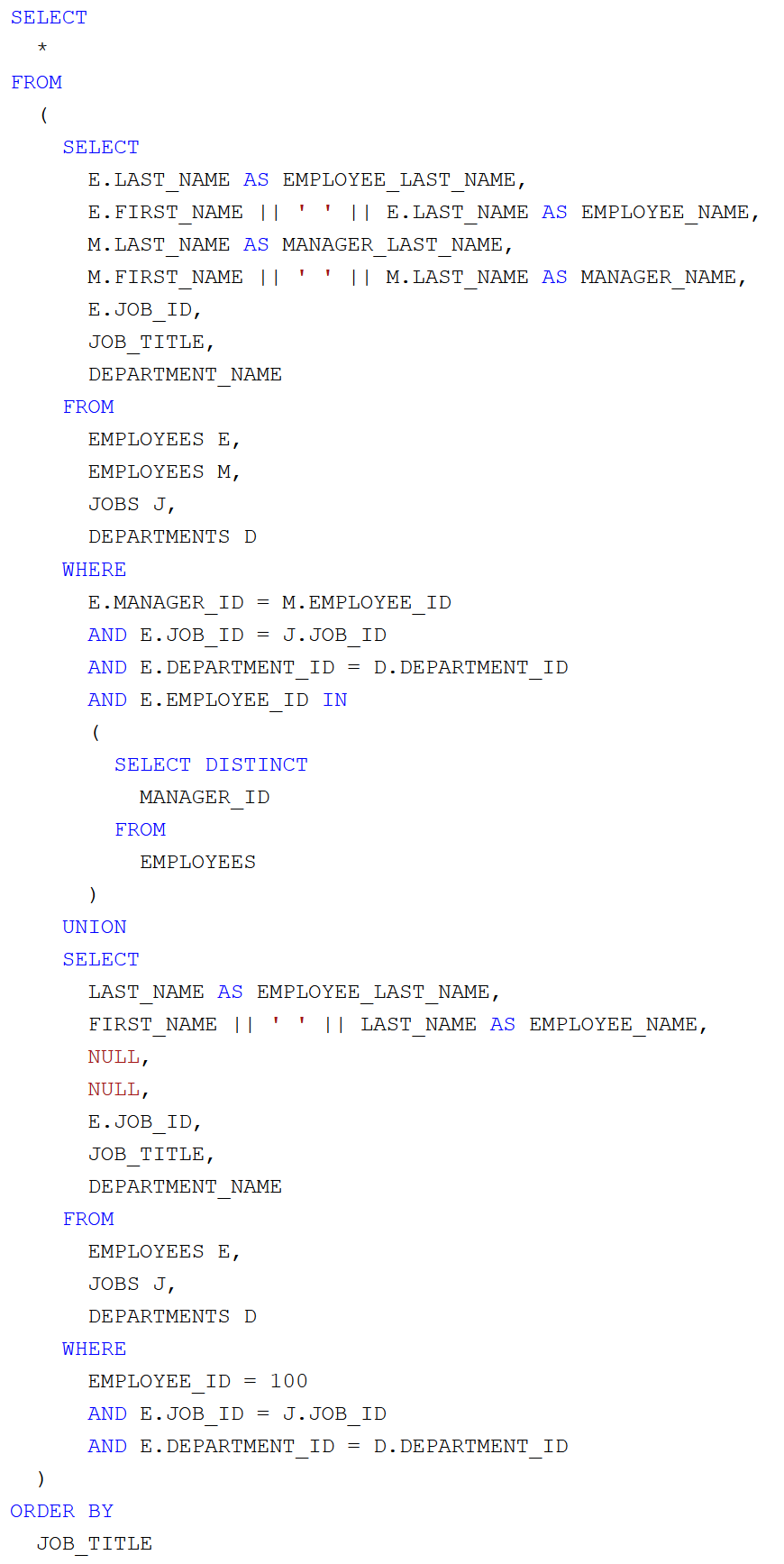
A lekérdező parancs
Az
EMPLOYEE_ID elsődleges kulcs, vagyis kötelező. A
MANAGER_ID nem kötelező, a hierarchia tetején álló vezetőnél ez a mező null értékű. Mivel a
MANAGER_ID nem kötelező, így külön lekérdező parancsban kell előállítani a 15 középvezetőt együtt a 2 felső vezetővel, valamint az egyetlen felső vezetőt, akinek a
MANAGER_ID-ja null. Ezt a két részeredményt össze kell fűzni (
UNION).
Az eredménytábla
Az adatfeldolgozás lépései
Java programozási nyelven kötelező a kivételkezelés a JDBC kapcsolatfelvétel, SQL parancs futtatása, valamint a fájlkezelés során. A
JDBCConnection interfészben definiált szöveges konstansok:
DRIVER,
URL,
USER,
PASSWORD (az adatbázis-szerverrel való kommunikációhoz),
SQL (a lefuttatandó lekérdező parancs). Az
OrganizationChart interfészbe került a
HTML_FILE_PATH (a generálandó HTML fájl
Path útvonala) és a
HTML (konstans váz az organogram testre szabott HTML+JavaScript forráskódja). Az SQL parancs
ResultSet eredménytáblájának feldolgozása során áll elő az
orgChartDataList generikus lista. A HTML konstans szövegben lévő
#OrgChartData# elemet ki kell cserélni a generikus listából Stream API-val dinamikusan összefűzött adatokra. A fenti példa ide kapcsolódó része:
"[{'v':'Raphaely', 'f':'Raphaely<div style="color:red;font-style:bold">PU_MAN</div>'}, 'King', 'Employee: Den Raphaely, Department: Purchasing, Job: Purchasing Manager']". Ezt követően a
java.nio csomag
Files osztályának
write() metódusával fájlba menthető az előállított fájltartalom. A konkrét Java forráskódot most nem részletezem.
Az elkészült organogram
A bejegyzéshez tartozó teljes forráskódot ILIAS e-learning tananyagban tesszük elérhetővé tanfolyamaink résztvevői számára.
Weboldalunkon cookie-kat (sütiket) használunk, melyek célja, hogy teljesebb szolgáltatást nyújtsunk látogatóink részére. További böngészésével hozzájárul ezek használatához. ElfogadAdatkezelési szabályzat
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.










 Az Oracle HR sémából építünk organogramot, amivel megjeleníthető a szervezeti hierarchia. Személyenként készítünk csomópontokat. (Másképpen is lehetne: például részlegenként.) A megvalósítás során kétszer konvertálunk A-ból B-be. Először az adatbázisból/adatforrásból SQL lekérdezéssel jutunk hozzá a szükséges adatokhoz, amelyeket generikus listába képezzük le. Ezután a listát feldolgozva generálunk HTML fájlt, amely tartalmaz egy
Az Oracle HR sémából építünk organogramot, amivel megjeleníthető a szervezeti hierarchia. Személyenként készítünk csomópontokat. (Másképpen is lehetne: például részlegenként.) A megvalósítás során kétszer konvertálunk A-ból B-be. Először az adatbázisból/adatforrásból SQL lekérdezéssel jutunk hozzá a szükséges adatokhoz, amelyeket generikus listába képezzük le. Ezután a listát feldolgozva generálunk HTML fájlt, amely tartalmaz egy