Hasonlítsuk össze a részlegeket fókuszálva arra, hogy az alkalmazottak mennyire vettek korábban részt projektmunkákban! Hányan igen és hányan nem? Van(nak) olyan részleg(ek), amelyik vezetője egyetlen alkalmazottat sem vont be projektmunkába? Van(nak) olyan részleg(ek), ahonnan mindenki csatlakozott? Vannak a feladatkiosztásban olyan aránytalanságok, amelyek kimutathatók és így a későbbiek során korrigálhatók? Készítsünk egy kimutatást arról, hogy részlegenként hány fő vett részt projektmunkában és mi a létszám! (Persze tudjuk, hogy nem minden munkakörből vonhatók be alkalmazottak.) Milyen projektjeink szoktak lenni? Van olyan részleg, ahol érdemes bővíteni a létszámot, esetleg átcsoportosítani oda erőforrást? Ezekre a kérdésekre keressük a választ.
Hasonlítsuk össze a részlegeket fókuszálva arra, hogy az alkalmazottak mennyire vettek korábban részt projektmunkákban! Hányan igen és hányan nem? Van(nak) olyan részleg(ek), amelyik vezetője egyetlen alkalmazottat sem vont be projektmunkába? Van(nak) olyan részleg(ek), ahonnan mindenki csatlakozott? Vannak a feladatkiosztásban olyan aránytalanságok, amelyek kimutathatók és így a későbbiek során korrigálhatók? Készítsünk egy kimutatást arról, hogy részlegenként hány fő vett részt projektmunkában és mi a létszám! (Persze tudjuk, hogy nem minden munkakörből vonhatók be alkalmazottak.) Milyen projektjeink szoktak lenni? Van olyan részleg, ahol érdemes bővíteni a létszámot, esetleg átcsoportosítani oda erőforrást? Ezekre a kérdésekre keressük a választ.
Tervezés
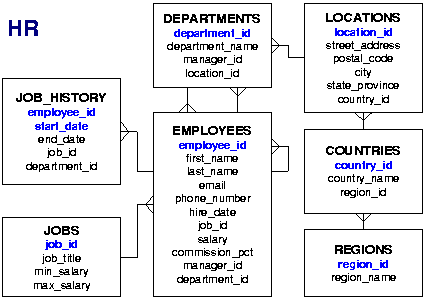
Az Oracle HR sémában három tábla kapcsolódik a feladathoz:
JOB_HISTORY,
EMPLOYEES,
DEPARTMENTS. A kapcsolatok fokszámai láthatók az alábbi ábrán. Egy részlegben több alkalmazott is lehet. Egy alkalmazott részt vehetett korábban több projektmunkában is.
A
DEPARTMENTS táblában található a részleg azonosítója (
DEPARTMENT_ID, kulcs) és neve (
DEPARTMENT_NAME). A többi adat most nem kell. 11 olyan részleg van, amihez tartozik alkalmazott.
A
JOB_HISTORY tábla tárolja, hogy a már befejeződött projektekben ki (
EMPLOYEE_ID, külső kulcs) és melyik részlegből (
DEPARTMENT_ID, külső kulcs) vett részt. A dátumokat (
START_DATE,
END_DATE) és a munkakör külső kulcsát (
JOB_ID) most nem használjuk. Minden projekt lezárt. 10 lezárt projekt van.
Az
EMPLOYEES táblából szükséges az alkalmazott azonosítója (
EMPLOYEE_ID, kulcs), valamint részlegének azonosítója (
DEPARTMENT_ID, külső kulcs). A többi adatra most nincs szükség, de egy részletesebb – például név szerinti – kimutatáshoz már igen. 106 olyan alkalmazott van, akihez tartozik részleg (1-nek nincs).
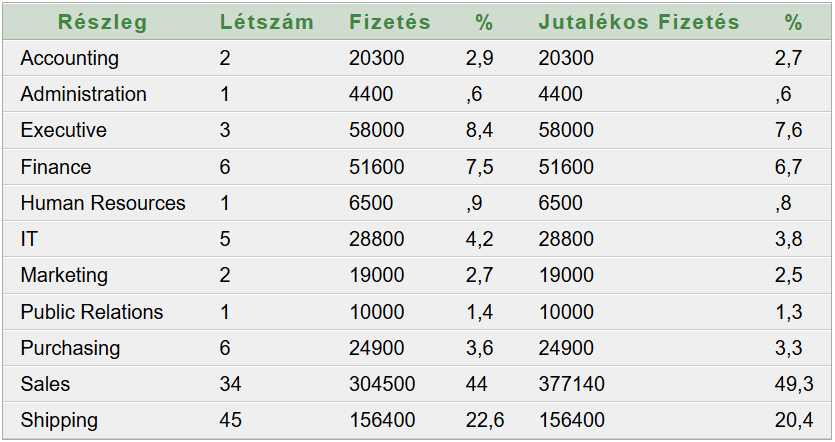
Hozzunk létre négy oszlopból álló eredménytáblát:
DEPARTMENT_ID,
DEPARTMENT_NAME,
COUNT_PROJECT_EMPLOYEES,
COUNT_EMPLOYEES. Ennek áttekintésével választ kaphatunk a fenti kérdésekre.
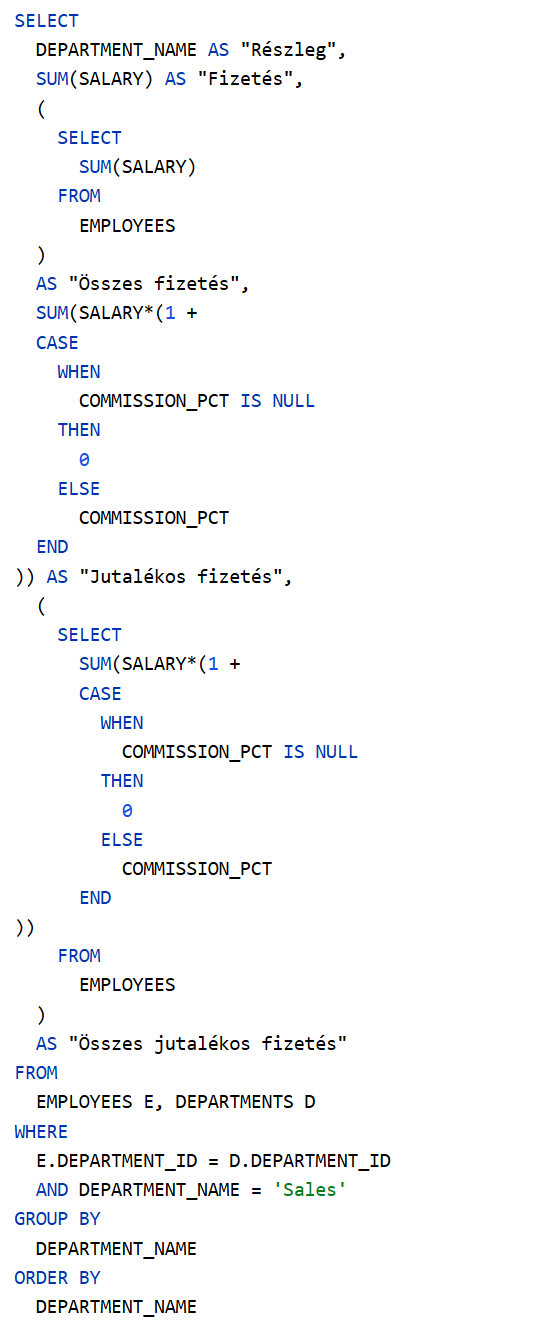
1. megoldás
Induljunk ki abból, hogy a
JOB_HISTORY táblában lévő
DEPARTMENT_ID-hez hozzárendeljük a
DEPARTMENTS táblából a
DEPARTMENT_NAME-t. Ezekre csoportosítva könnyen aggregálható az adott részlegből projektmunkát végző alkalmazottak száma:
COUNT_PROJECT_EMPLOYEES. Végül egy belső lekérdezés (összekapcsolva a
JOB_HISTORY és az
EMPLOYEES táblákat) megadja az adott részleg alkalmazotti létszámát. Az SQL lekérdezés:

A részeredmény:
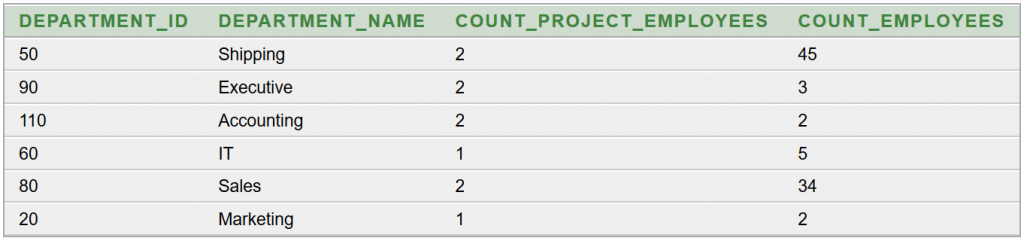
Ezután állítsuk elő a hiányzó adatokat! Tudjuk, hogy azokban a részlegekben, amelyek
DEPARTMENT_ID-je nem szerepel a
JOB_HISTORY táblában, de szerepel az
EMPLOYEES táblában, azok léteznek, de nem „adtak” projektmunkára alkalmazottat (azaz
COUNT_PROJECT_EMPLOYEES=0). Nevük és alkalmazottaik száma ugyanúgy megadható, ahogyan az előbb. Az SQL lekérdezés:
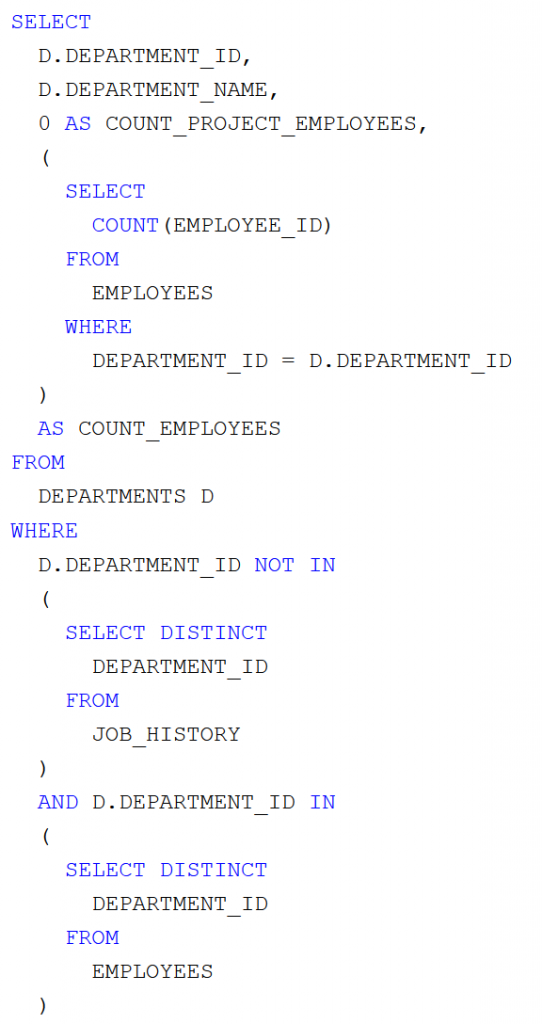
A részeredmény:
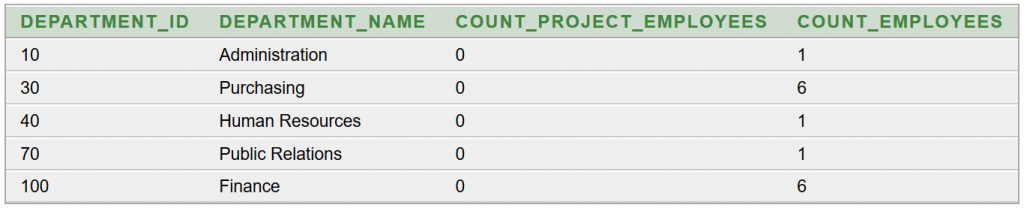
A két részeredményt egyesíteni kell és egyben hasznos
DEPARTMENT_NAME szerint növekvő sorrendbe rendezni az alábbi lekérdező paranccsal:
Az eredmény:
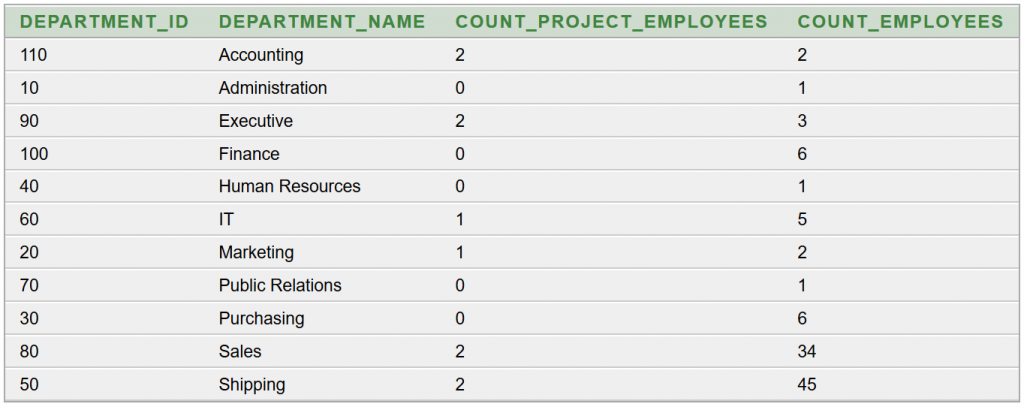
2. megoldás
Kiindulhatunk abból is, hogy a
DEPARTMENTS egy szótártábla, így közvetlenül hozzáférhető a
DEPARTMENT_ID és a
DEPARTMENT_NAME, de össze kell kapcsolni az
EMPLOYEES táblával, hogy csak olyan részlegeket adjon vissza a lekérdezés, ahol van(nak) alkalmazott(ak). Az eredményhez szükséges további két oszlop könnyen aggregálható az adott részlegre vonatkozóan: a
JOB_HISTORY táblában előforduló
EMPLOYEE_ID-k száma adja a
COUNT_PROJECT_EMPLOYEES-t (probléma nélkül tud 0 lenni) és az
EMPLOYEES táblában előforduló
EMPLOYEE_ID-k száma adja a
COUNT_EMPLOYEES-t. A rendezés most is szükséges. Lényegesen tömörebb lekérdező parancsot kapunk:
Az eredményül kapott táblázat megegyezik az 1. megoldás eredményével.
A két megoldás teljesen különböző gondolatmenettel született. Mindkettőben vannak olyan elemek, amelyek – konkrét feladatból általánosítva – univerzálisan használhatók. Természetesen összehasonlítjuk a két megoldás végrehajtási tervét és részletesen elemezzük is.
A bejegyzéshez tartozó teljes forráskódot ILIAS e-learning tananyagban tesszük elérhetővé tanfolyamaink résztvevői számára.
A feladat a Java adatbázis-kezelő tanfolyam 9-12. óra: Oracle HR séma elemzése, 13-16. óra: Konzolos kliensalkalmazás fejlesztése JDBC alapon, 1. rész, 33-36. óra: Grafikus kliensalkalmazás fejlesztése JDBC alapon, 2. rész alkalomhoz kapcsolódik.