
![]() Letöltési folyamatot szimulálunk. A paraméterek rugalmasan beállíthatóak. Előre beállított mennyiségű adatot, párhuzamos szálakon/folyamatokon keresztül töltünk le, miközben mérjük az eltelt időt. A folyamatok állapota lehet inaktív, aktív és befejezett. Az aktív folyamatok esetében megjelenő százalék fejezi ki, hogy a folyamat hol tart a rá jutó részfeladat végrehajtásával. Összesített formában követhetjük a hiányzó és a letöltött adat mennyiségét MB-onként és százalékosan is. A folyamat szimulációjához grafikus felületű Java kliensprogram készült, egyszerű GUI komponensekkel (nyomógomb, címke, folyamatindikátor, másképpen
JButton,
JLabel,
JProgressBar swing komponensek).
Letöltési folyamatot szimulálunk. A paraméterek rugalmasan beállíthatóak. Előre beállított mennyiségű adatot, párhuzamos szálakon/folyamatokon keresztül töltünk le, miközben mérjük az eltelt időt. A folyamatok állapota lehet inaktív, aktív és befejezett. Az aktív folyamatok esetében megjelenő százalék fejezi ki, hogy a folyamat hol tart a rá jutó részfeladat végrehajtásával. Összesített formában követhetjük a hiányzó és a letöltött adat mennyiségét MB-onként és százalékosan is. A folyamat szimulációjához grafikus felületű Java kliensprogram készült, egyszerű GUI komponensekkel (nyomógomb, címke, folyamatindikátor, másképpen
JButton,
JLabel,
JProgressBar swing komponensek).
Az alábbi animáció bemutatja a letöltés szimulációját:
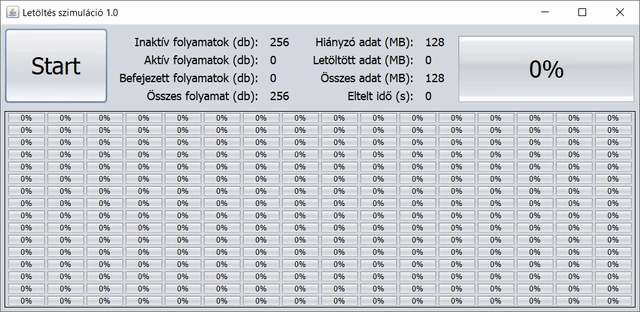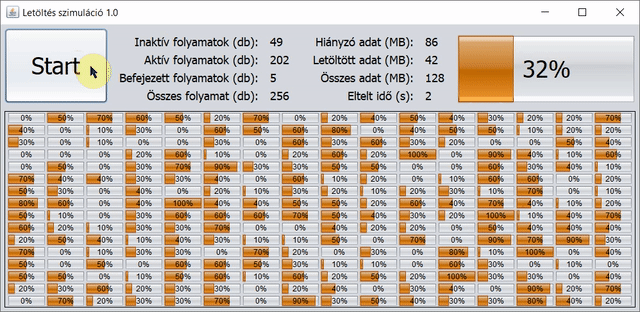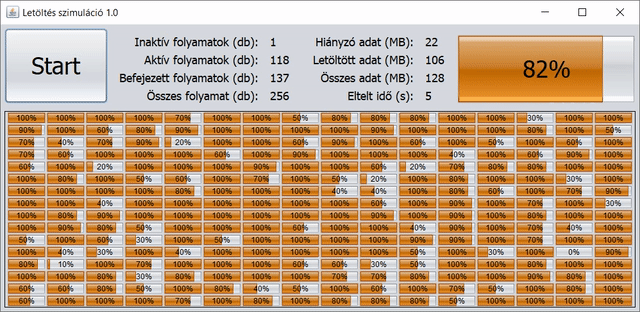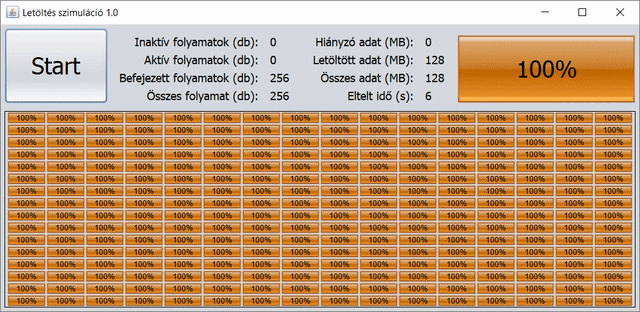
A konkrét paraméterek: 128 MB-nyi adatot töltünk le 256 párhuzamos szálon/folyamaton keresztül, így egy-egy részfeladat 0,5 MB-nyi adat letöltését jelenti. Minden értéket/mérőszámot egész számként ábrázolunk, akár százalékhoz tartozik, akár mértékegységként MB vagy s. A változások – és egyben a frissítés is – 5 ezredmásodpercként történnek a GUI-n.
A Java SE szoftverfejlesztő tanfolyamunkon, a szakmai modul Objektumorientált programozás témakörét követő 29-36. óra Grafikus felhasználói felület alkalmain már tudunk egyszerűbb szimulációs programot tervezni, kódolni, tesztelni. A Java EE szoftverfejlesztő tanfolyamunkon, a szakmai modul 5-8. óra Szálkezelés, párhuzamosság alkalommal többféle elosztott stratégiát ismertetünk, és a 17-24. óra Socket és RMI alapú kommunikáció alkalommal pedig megvalósíthatjuk többféle protokoll szerint a hálózati kapcsolatot, letöltést/feltöltést.
Elosztott alkalmazások esetén többféleképpen is modellezhető és kialakítható a rendszer architektúrája. Elosztott lehet maga a hálózat, a számítási folyamat, az algoritmus. Elosztott objektumok kommunikálhatnak egyenrangúnak tekinthető P2P szerepkörben vagy szerver/kliens oldalon, és több dolog/elem/hardver/szoftver/komponens együttműködéseként is megvalósulhat elosztott alkalmazás. A hálózati kommunikáció folyamatát valamilyen protokoll határozza meg, amit minden komponens ismer és így meghatározott szabályrendszer szerint működik.
Hardver szinten elosztottak a többprocesszoros rendszerek. Szoftveresen elosztott például egy moduláris vállalatirányítási rendszer, illetve a mobilalkalmazások többsége. Tipikus háromrétegű webalkalmazás esetén külön szerver nyújtja az adatbázishoz kapcsolódó szolgáltatásokat, a felhasználó számítógépén található a böngészőben futó/megjelenő kliensprogram/weboldal és a kettő között a felhő rétegben lehet a funkcionálisan elosztott alkalmazáslogika (például validálás, titkosítás, tömörítés, autentikáció, autorizáció).
A vezérlést megvalósító részlet a Java forráskódból:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
private void processControl() { if(processList.isEmpty()) { timer.stop(); return; } int index=(int)(Math.random()*processList.size()); int oldValue=processList.get(index).getValue(); int increase=(int)(Math.random()*3+1)*10; //5, 10, 15 increase=oldValue+increase<=MAX ? increase : MAX-oldValue; downloadedSumPercent+=increase; int newValue=oldValue+increase; processList.get(index).setValue(newValue); if(newValue==MAX) processList.remove(index); int openProcessCount=0, inactiveProcessCount=0; for (JProgressBar pb : processList) { int v=pb.getValue(); if(v==MIN) inactiveProcessCount++; if(MIN<v && v<MAX) openProcessCount++; } lbInactiveProcessCount.setText(""+inactiveProcessCount); lbOpenProcessCount.setText(""+openProcessCount); lbClosedProcessCount.setText(""+ (PROCESS_COUNT-(openProcessCount+inactiveProcessCount))); int downloadedData= (int)((double)downloadedSumPercent/(PROCESS_COUNT*MAX)*DATA); lbMissingData.setText(""+(DATA-downloadedData)); lbDownloadedData.setText(""+downloadedData); pbProcess.setValue((int)((double)downloadedData/DATA*100)); elapsedTime+=5; if(elapsedTime%1000==0) lbElapsedTime.setText(""+elapsedTime/1000); } |
A szimuláció elvi szinten:
- a folyamatok generikus listában vannak,
- időzítő által meghatározottan, gyorsan és ismétlődve történnek az időzített lépések,
- ha egy folyamat befejeződik, akkor kikerül a generikus listából,
- ha a folyamatok generikus listája kiürült, akkor vége a szimulációnak,
- ki kell választani véletlenszerűen egy folyamatot, léptetni kell véletlenszerűen, amíg be nem fejeződik,
- folyamatosan nyilván kell tartani a szükséges adatokat a háttérben,
- folyamatosan frissíteni kell a felhasználói felületet.
Haladóbb megközelítésben másképp is lehetne: a számítási műveletek redukálhatóak lennének, ha lenne egy – minden olyan adat karbantartásáért felelős – modellobjektum, amelynek adatai hozzá lennének rendelve a GUI komponensekhez. Aki már sejti, annak megerősítem, hogy igen, ez observer (megfigyelő) tervezési minta.
A feladat könnyen általánosítható, például:
- Egy keresési feladatot oldjunk meg az állományrendszerben! Kereshetünk egy konkrét nevű fájlt, adott kiterjesztésű fájlt, joker karakterekkel paraméterezett nevű fájlt/mappát, adott méretű állományt, adott dátum előtt létrehozott fájlt… Az állományrendszer bejárása rekurzív módon történik. A gyökérben lévő mappánként külön, esetleg második szinten lévő mappánként külön indíthatók szálak, párhuzamos folyamatok. Ha egyetlen találat elegendő, akkor bármelyik szál pozitív visszajelzésére minden szál leállítható. A feladatnál nagy eséllyel nagyon különböző méretű mappákon és eltérő mélységű mappaszerkezeteken kell végighaladni, így erre érdemes lehet optimalizálni, de ez már nagyon más szintje ennek a problémának.
- Active Directory szerkezetben keressünk elérhető nyomtatókat a hálózaton!
- Elosztott számítási hálózatként működik/működött a SETI@home. Koncepciójának lényege, hogy egy hatalmas feladatot nem nagyon drága szuperszámítógépeken, hanem olcsó gépek ezrein, százezrein, vagy akár millióin végeztetjük el, amelyek jelentős szabad kapacitással (pl. processzoridővel, átmeneti tárhellyel) rendelkeznek és egyébként is csatlakoznak a világhálóra.
- Hasonlóan elosztott működésű a torrent protokoll. A kliensek/szálak az állományokat több kisebb darabban/szeletben töltik le, természetesen párhuzamosítva. Minden csomópont megkeresi a hiányzó részhez a lehető leggyorsabb kapcsolatot, miközben saját maga is letöltésre kínálja fel a már letöltött fájldarabokat. A módszer nagyon jól beválik nagyméretű fájloknál, például videók esetében. Minél népszerűbb/keresettebb egy fájl, annál többen vesznek részt az elosztásában, ezáltal a letöltési folyamat gyorsabb, mintha mindenki egy központi szerverről töltené le ugyanazt (hiszen az informatikában minden korlátos, a sávszélesség is).
- A képtömörítést végző algoritmusok is lehetnek elosztottak, ezáltal párhuzamosíthatóak. Például ha felosztjuk a képet 16*16-os méretű egymást nem átfedő részekre, akkor ezek egymástól függetlenül tömöríthetők.
- A merevlemezek esetén korábban használatos defragmentáló szoftverek felhasználói felülete emlékeztet a mintafeladat ablakára.
Fontos szem előtt tartani, hogy a grafikus megjelenítés csupán a szimulációhoz tartozó – annak megértéséhez szükséges – reprezentáció, így teljesen független lehet a folyamatok valós működésétől.
A bejegyzéshez tartozó teljes forráskódot ILIAS e-learning tananyagban tesszük elérhetővé tanfolyamaink résztvevői számára.





Akit a szimuláció mélyebben érdekel, itt egy BME-s tananyag:
Aradi, Gräff, Lipovszki (2014): Számítógépes szimuláció
Némi nosztalgia, hogyan működött régen a defrag DOS parancs:
https://www.youtube.com/watch?v=lxZyxxHOw3Y
Szemléletes a példád Zoli, köszönöm. Mi mindenre voltak képesek régen, karakteres képernyőn! Ma már sokkal könnyebb a dolgunk a GUI komponensekkel.
Sok kérdőív több lapos és a lapok alsó részén gyakran van folyamatjelző. Milyen lehetőségek vannak itt a léptetésre?
Kétféle megoldást láttam eddig Marcell, de biztosan akad még: