Címke: dátumkezelés
10 blog bejegyzésnél szerepel:
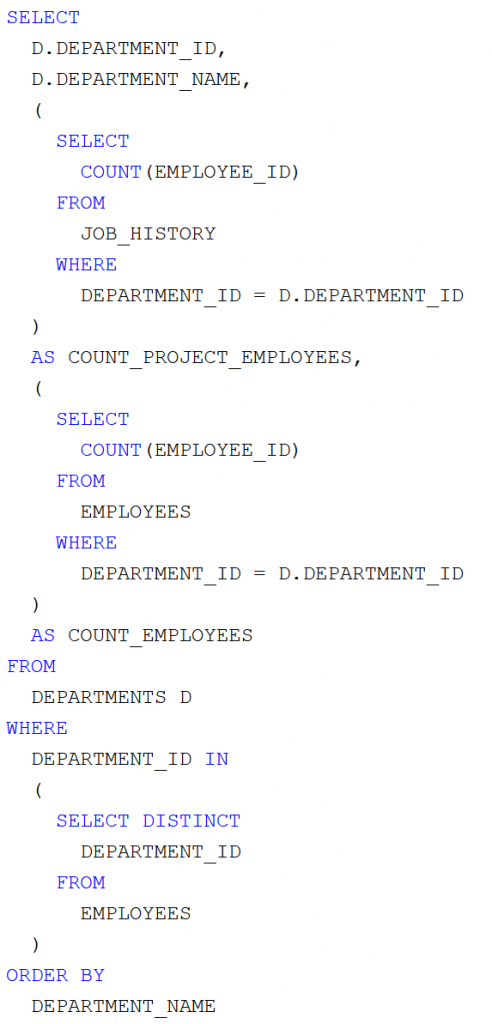
![]() Tankocka – Rövid válasz: Java konstansok
Tankocka – Rövid válasz: Java konstansok
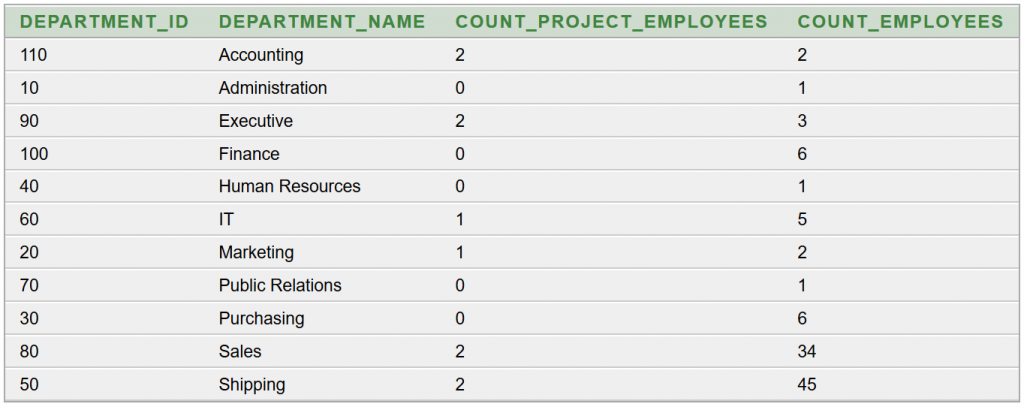
![]() Kik vettek részt projektmunkában?
Kik vettek részt projektmunkában?





68 db hozzá kapcsolódó címke:
2017 (24), 2018 (24), 2020 (24), 2021 (24), 2022 (24), 2023 (24), adatbázis (25), algoritmus (31), AnyChart (1), atipikus megoldás (5), ciklusok (18), csoportváltás (6), élményalapú tanulás (21), elosztott alkalmazás (14), eredménytábla (10), évforduló (24), fájlkezelés (29), fejtörő (11), funkcionális programozás (18), gamifikáció (33), Google Charts (5), Google Cloud Platform (2), grafika (26), grafikus felhasználói felület (40), hálózatkezelés (14), hatékonyság (28), húsvétvasárnap (1), időjárás (2), Java forráskód (63), JavaScript (6), JDBC (12), JSON (4), kivételkezelés (13), kódolás/dekódolás (6), kollekció (32), kombinatorika (7), könyvajánló (4), lambda kifejezés (13), lekérdezés (18), lépésszám (9), logikai feladat (21), matematika (30), metódus (30), naptár (26), objektumorientált programozás (85), OpenWeatherMap (2), Oracle HR séma (12), öröklődés (16), osztálydiagram (7), péntek 13 (1), programozás (106), programozási tételek (28), projektmunka (5), rekurzió (9), SQL forráskód (12), statisztika (11), Stream API (14), swing (26), szakmai modul (96), táblázat (11), tankocka (15), térinformatika (4), tervezés (41), tesztelés (21), többféle megoldás összehasonlítása (37), tömb (17), továbbfejlesztés (23), ünnepnap (13)
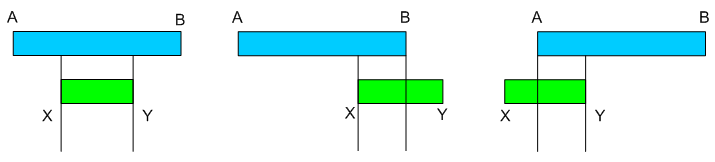
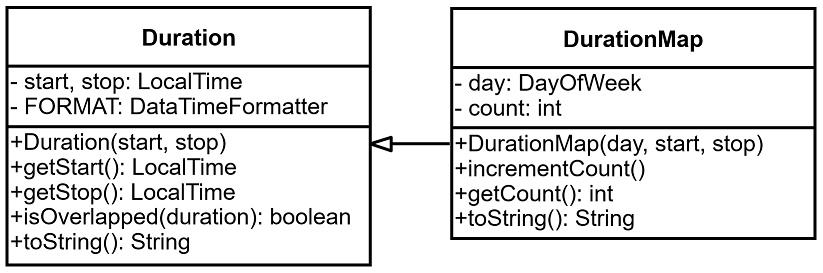 A
A
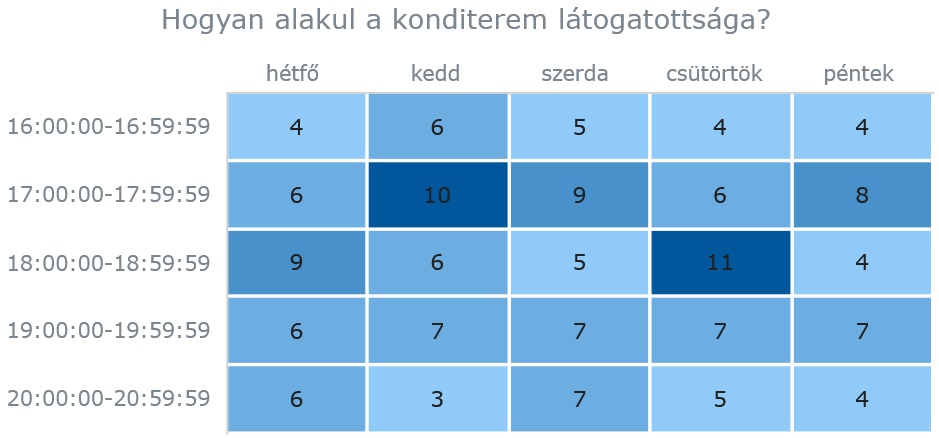
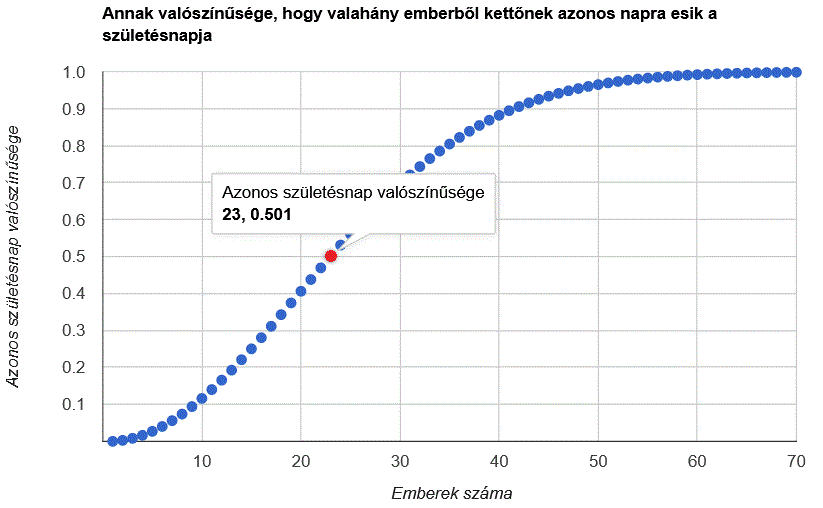
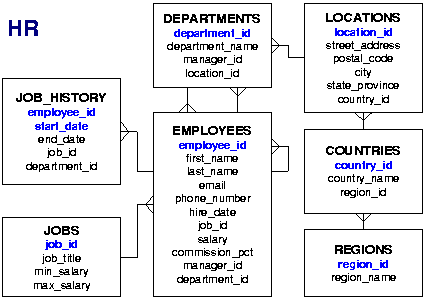

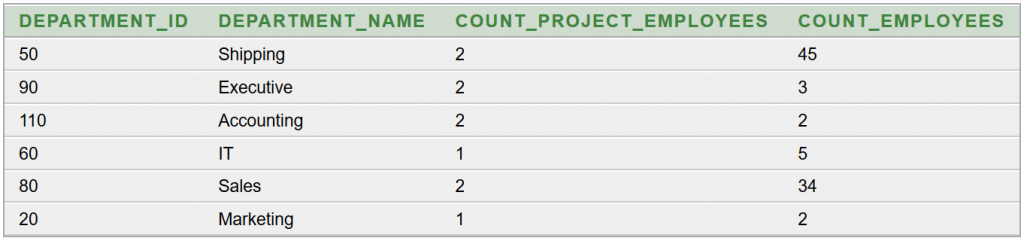
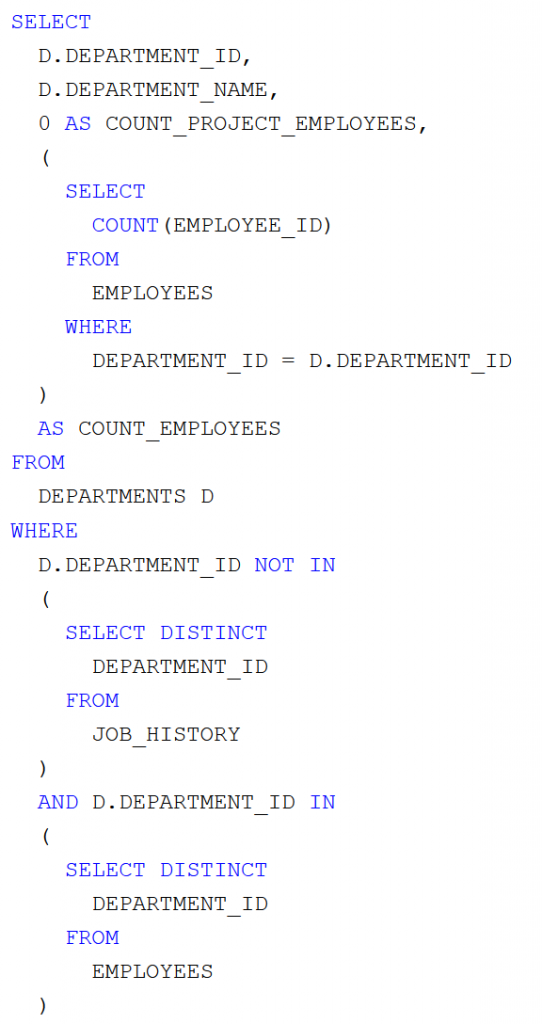
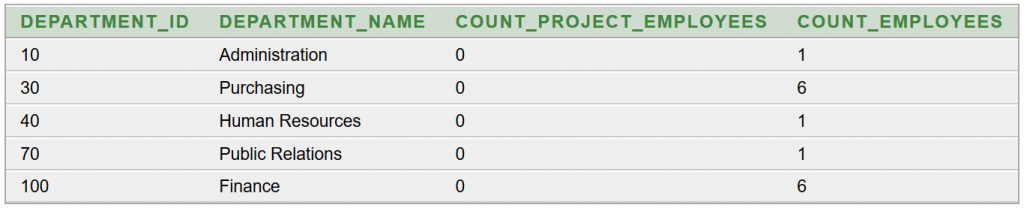
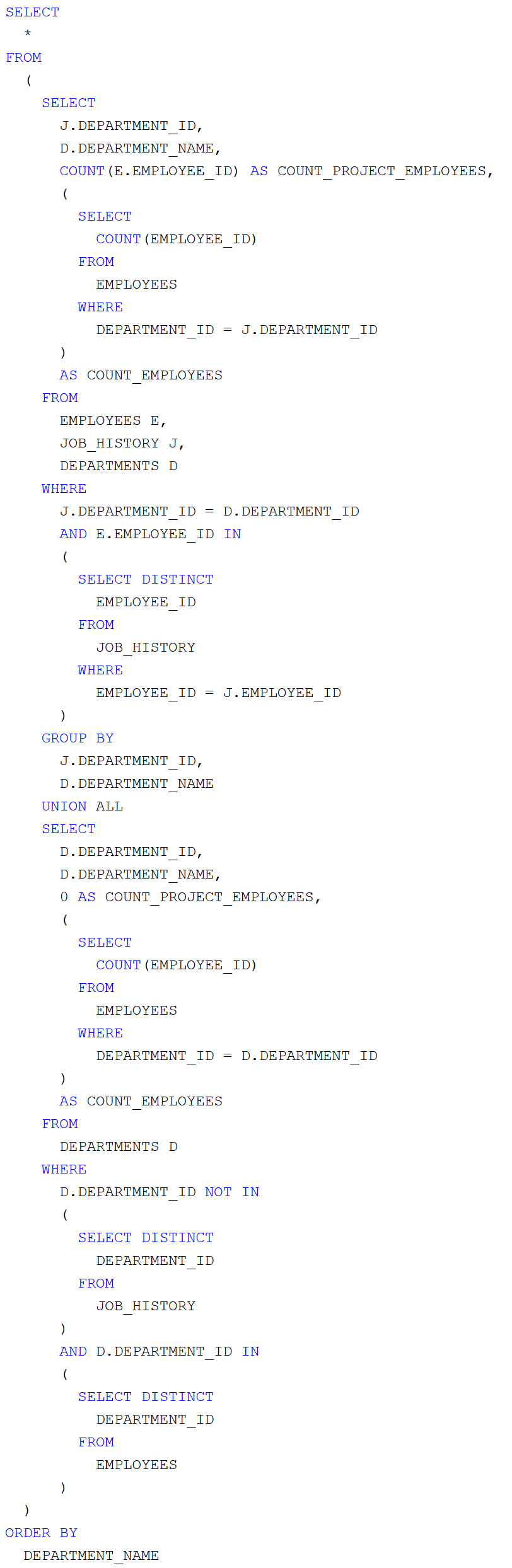
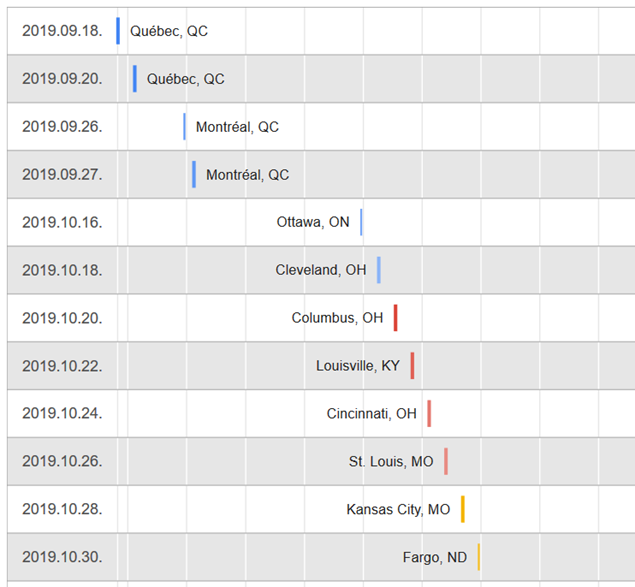
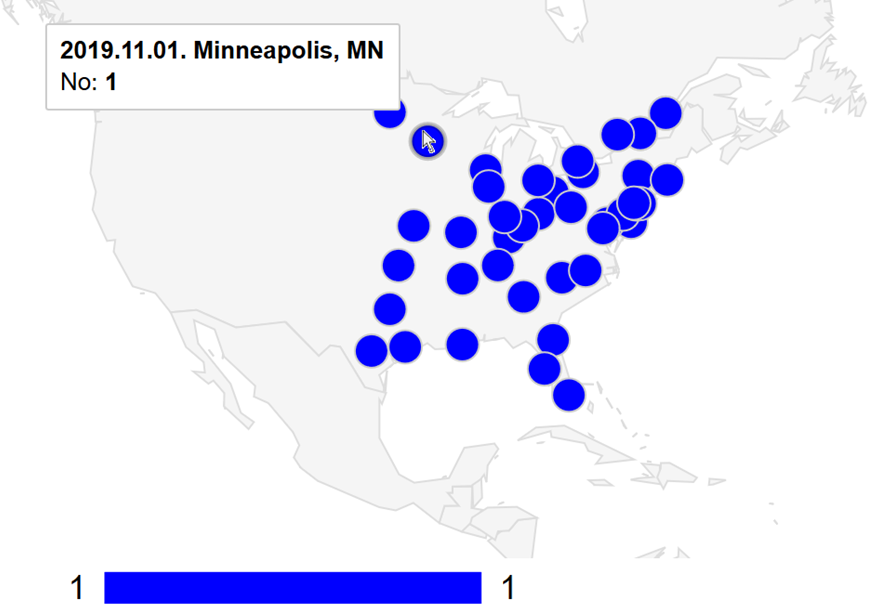
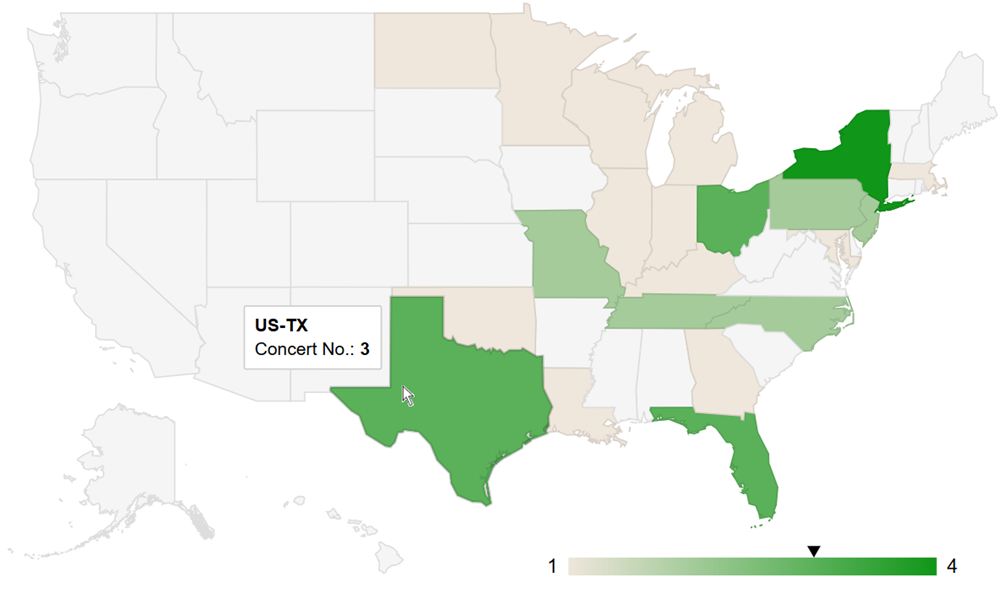
 A Céline Dion – Courage World Tour esettanulmányunkban a turné első részének koncerthelyszíneit jelenítjük meg Google Charts segítségével. Ebben a blog bejegyzésben a tervezés, megvalósítás lépéseit tekintjük át és megmutatjuk az eredményeket. A Java és JavaScript forráskódokat most nem részletezzük.
A Céline Dion – Courage World Tour esettanulmányunkban a turné első részének koncerthelyszíneit jelenítjük meg Google Charts segítségével. Ebben a blog bejegyzésben a tervezés, megvalósítás lépéseit tekintjük át és megmutatjuk az eredményeket. A Java és JavaScript forráskódokat most nem részletezzük.