Saját doktorandusz csoporttársaimmal én is többször beszélgettem már arról – ahogyan Sándor is tette 2018-ban –, hogyan tudnák/tudják használni a programozás eszköztárát, módszereit, lehetőségeit saját kutatási munkájukban, beépítve a kutatási folyamat egyes lépéseibe, illetve disszertációjuk elkészítésébe.
A 7 fős csoportban mindenkinek más az alapvégzettsége, így szoftverfejlesztéshez, programozáshoz közös szókincs és terminológia haladó szinten természetesen nincs, viszont közös bennünk, hogy mindannyian alkotunk különféle modelleket és elemzünk adatokat. A csoport teljesen inhomogén, több szempontból is: ki melyik évfolyamot végzi, hol tart a kutatómunkájában, vannak-e ipari kapcsolatai, nappali vagy levelező képzésben végzi tanulmányait és persze ki mikor ér rá.
Különféle modelleket alkotunk
a mérnökök, fizikusok, geográfusok, biológusok többféle kísérletet végeznek el, szimulációkat terveznek és futtatnak, mérőeszközöket és műszereket használnak,
az informatikusok különböző matematikai eszközöket alkalmazva objektumorientált – vagy másféle – modellezést végeznek, szoftvereket terveznek, javítanak, újraírnak.
Adatokat is elemzünk, ki-ki előképzettségének megfelelően
Az öt évvel ezelőtti tematikát újragondoltuk. Kérdőívben felmértük a csoporttársak koncepcionális és konkrét igényeit. Más doktori iskolák hallgatói közül is toboroztunk. Ehhez kötődően köszönjük a DOSZ segítségét. Ezek alapján összeállítottunk egy olyan 3 részből álló tematikát, ami mindannyiunk számára hasznos. A 72 óra három 24 órás modulból áll: Java programozás, MATLAB programrendszer, mesterséges intelligencia.
Java programozás modul
1-6. óra: Objektumorientált modellezés, MVC rétegek, algoritmus- és eseményvezérelt programozás
7-12. óra: Fájlkezelés és szövegfeldolgozás (XLS, CSV, XML, JSON formátumú adatok írása, olvasása, feldolgozása), helyi és távoli adatforrásból
13-18. óra: Adatbázis-kezelés JDBC alapon (SQL parancsok, CRUD műveletek, hierarchikus lekérdezések), helyi és távoli adatforrásból, natív módon és készen kapott API-kkal
19-24. óra: Komplex adatfeldolgozási feladatok megoldása programozási tételek használatával, egyszerű statisztikai funkciók implementálásával
MATLAB programrendszer modul
1-6. óra: Bevezetés az MATLAB nyelvbe (R2012 vs. R2022), utasításkészlet, vektorok, mátrixok, szkriptek, függvények, grafika
13-18. óra: Adatok importálása helyi és távoli adatforrásból is, fájlkezelés: szövegfájlok, Excel-fájlok, import, feldolgozás, export, statisztikai alapok
1-6. óra: Klasszikus és újabb megközelítések, alap AI funkcionalitás, megerősítéses és gépi tanulás lehetőségei és korlátai, OpenAI GPT nyelvi modell
7-12. óra: Általános csevegés lehetőségei, korlátai, hasznos tanácsok; csevegés fájlok (szöveg, multimédia) tartalmáról; generatív AI funkciói; kép, ábra, grafikon, térkép, hang, animáció, videó generálása és ezek tömeges feldolgozása; programozási tételek alkalmazása multimédia analitikával együtt
13-18. óra: Statisztikai adatok elemzése AI eszközökkel, automatikus tételbizonyítás AI eszközökkel, gráfelméleti kérdések kontra AI, hatékonysághoz kötődő kérdések AI eszközök esetén
19-24. óra: Objektum- és aspektusorientált tervezés AI eszközökkel, kutatómunkát támogató AI eszközök
Mivel mindenki doktorandusz a csoportban, így a különböző MSc-s alapvégzettsége ellenére mindannyiunknak vannak strukturális programozáshoz kötődő alapismeretei, valamint adatok elemzéséhez szükséges elméleti matematikai/statisztikai alapjai.
A csoport órái szeptembertől decemberig, szombatonként zajlottak. Sándor tartotta a 24 órás Java programozás modult. Ez nagyban lefedi a Java SE szoftverfejlesztő tanfolyamunk tematikáját és kapcsolódik a Java EE szoftverfejlesztő tanfolyamunk és a Java adatbázis-kezelő tanfolyamunk tematikájához is. Én tartottam a 24 órás MATLAB programrendszer modult. Ketten közösen tartottuk a 24 órás Mesterséges intelligencia modult. Igazán tartalmas őszi időszakot jelentett számunkra ez a 12 szombat. Mindenki elvitte, amit beletett.
A koncepciót once-in-a-lifetime jelleggel dolgoztuk ki 🙂 (újratöltve) azzal a fő szándékkal, hogy hatékonyabban működjünk együtt a jövőben. A visszajelzések alapján bátran állíthatom, hogy ez gördülékenyen fog menni. Egyben köszönöm mindenkinek az aktív, konstruktív részvételt.
A rendezvény elsődleges célja annak elősegítése, hogy a felsőoktatási intézmények oktatói és kutatói a matematika, a fizika, az informatika és a logisztika korszerű és hatékony oktatásáról és tudományos eredményeiről előadások, poszter-bemutatók és személyes találkozás révén tapasztalatot cserélhessenek, valamint kapcsolatot építhessenek mind a hazai kollégákkal, mind a környező országok magyar ajkú oktatóival. A rendezvény célja továbbá, hogy fórumot adjunk PhD hallgatók eredményeinek bemutatására.
A konferencia tervezett főbb témakörei
a korszerű matematika-, fizika-, logisztika- és informatikatanítás és tanulás új útjai és távlatai, oktatásfejlesztési tapasztalatai,
a felsőoktatás alapozó tárgyainak oktatás-módszertani problémái,
mesterképzésbe való bekapcsolódás, a duális képzés gondjai és tapasztalatai,
matematika, fizika, informatika, logisztika tudományos eredményei,
új és innovatív kutatási irányok, problémák és gyakorlati alkalmazások bemutatása a fenti tudományterületeken.
A konferencia programja
A letölthető absztraktkötet tartalmazza a program- és szervezőbizottság által összeállított szakmai programot. A szerdai 5 plenáris előadást este bűvészprogram követte. Csütörtökön párhuzamos szekciókat tartottak: Matematika, Matematika oktatása, Fizika, Informatika, Logisztika, valamint poszterbemutató, mindezek után szakmai kirándulás volt Lakitelken a Hungarikum Ligetben planetáriumi bemutatóval, borkóstolóval, vacsorával. Pénteken a Matematika, Informatika szekciók után a konferenciát 2 plenáris előadás zárta. 20-nál több intézményből 100-nál több előadó regisztrált a rendezvényre.
Részt vettünk a konferencián
2023-ban két szakmai előadást tartottunk, 20-20 percben, a csütörtöki Informatika szekcióban.
Szakmai cikkeink a Gradus lektorált, online folyóiratban fognak megjelenni (ISSN 2064-8014), amely eredeti publikációkat közöl számos témakörben, beleértve a természettudományok minden területét, mindenféle műszaki tudományt, számítástechnikát, kertészetet, környezetmérnökséget, pedagógiát, didaktikát és közgazdaságtant.A számítástechnika és a matematika elméleti és alkalmazott területeit is befogadja.A folyóirat csak kutatási cikkeket közöl, és minden cikk az esettanulmányok, kísérletek, vagy a gyakorlatban már alkalmazott megközelítésekkel való szisztematikus összehasonlítások révén előrehaladó ötletek gyakorlati alkalmazását tárgyalja.
Szakmai előadásaink összefoglalói
Kaczur Sándor, Friedel Attila – Hogyan érdemes nagy tömegű adatot importálni Microsoft .NET Framework platformon?
Üzleti alkalmazások fejlesztésénél elengedhetetlen alkotóelem az adatok kezelése, tárolása. Ezt leggyakrabban valamilyen relációs adatbázis-kezelővel valósítják meg a fejlesztők. A hétköznapi munka során gyakran előforduló feladat külső forrásból történő adatok átvétele, aktualizálása. A cikk szerzői arra a kérdésre keresik a választ, hogy hogyan érdemes ezen (néha igen tetemes mennyiségű) adatokat minél gyorsabban átvenni. A bemutatásra kerülő esettanulmány Microsoft .NET Framework segítségével, a platform által kínált adatbázis-kezelési lehetőségek közül válogat. A cikk összehasonlítja a nyelvben már régóta jelen lévő alacsony szintű SQL parancsokkal végzett megvalósítást a később beépített, de szintén elterjedt objektumrelációs modell keretrendszerrel (azaz az Entity Framework-kel) történő megvalósítással, majd elemzi a kapott eredményeket.
Kaczur Sándor, Kiss Balázs – Alkalmazottak életpálya modellje – Java és SQL esettanulmány az Oracle HR sémára építve
Az objektumorientált programozás oktatásának része olyan kliensprogramok tervezése, kódolása és tesztelése, amelyek képesek adatbázishoz csatlakozni. A belépő szint csupán lekérdezés, adatok megjelenítése űrlapokon, táblázatos komponensekben, vagy grafikonokon. Haladó szinten már szükséges az adatok karbantartása is, illetve konzolos, asztali alkalmazásokról át lehet térni webes és mobil platformokra is. A szerzők cikke ebből az útból emel ki egy esettanulmányt, amely Java és SQL nyelveken készült és MVC architekturális tervezési mintát használ. A felhasznált mintaadatok az Oracle HR sémából származnak. Az elemzés betekintést nyújt a modellalkotás lehetőségeibe – többféle megközelítést alkalmazva, elvi és konkrét szinten is.
Az előadásaink témája a Java adatbázis-kezelős tanfolyam szakmai moduljához és orientáló moduljához is kapcsolódik. Az előadásaink prezentációit ILIAS e-learning tananyagban tettük elérhetővé tanfolyamaink résztvevői számára.
Korábbi MAFIOK előadásaink, cikkeink, posztereink
Kaczur S.: Az OracleHRJSP webalkalmazás működése, Matematikát, fizikát és informatikát oktatók (MAFIOK) XXXVIII. országos konferenciája, Pécs, Pécsi Tudományegyetem Pollack Mihály Műszaki és Informatikai Kar, 2014, ISBN 978-963-7298-55-4, p. 121-126 (magyar nyelvű szakcikk)
Kaczur, S.: A Gábor Dénes Tehetségpont programozáshoz kötődő diákműhelyei, Matematikát, fizikát és informatikát oktatók (MAFIOK) XXXVIII. országos konferenciája, Pécs, Pécsi Tudományegyetem Pollack Mihály Műszaki és Informatikai Kar, 2014. augusztus 25-27. (poszter hazai konferencián)
Kaczur, S.; Lengyel, B. I. (előadó: Kaczur, S.): A csomópont kiválasztás algoritmus működését bemutató oktatóprogram PLNC adatátvitel esetén, Matematikát, fizikát és informatikát oktatók (MAFIOK) XXXVIII. országos konferenciája, Pécs, Pécsi Tudományegyetem Pollack Mihály Műszaki és Informatikai Kar, 2014. augusztus 25-27. (poszter hazai konferencián)
Kaczur, S.: Nyílt forráskódú EKG analizáló algoritmusok hatékonysága (Signal analysis), Matematikát, fizikát és informatikát oktatók XXXVI. országos konferenciája (MAFIOK), Gyöngyös, Károly Róbert Főiskola, 2012. augusztus 27-29. (előadás hazai konferencián)
Kaczur, S.; Fintor, K.: Szerkezetföldtani oktatóprogram, vetőmenti elmozdulások modellezésére, Perspective, XV. évfolyam különszám, Szent István Egyetem Gazdasági Kar, 2011, ISSN 1454-9921, p. 215-222 (magyar nyelvű szakcikk)
Fintor, K.; Kaczur, S.: Vetőmozgások 3D-s szimulációjának alkalmazása a földtudományi képzésben, Perspective, XV. évfolyam különszám, Szent István Egyetem Gazdasági Kar, 2011, ISSN 1454-9921, p. 208-204 (magyar nyelvű szakcikk)
Kaczur, S.; Fintor, K. (előadó: Kaczur, S.): Szerkezetföldtani oktatóprogram, vetőmenti elmozdulások modellezésére, Matematikát, fizikát és informatikát oktatók XXXIV. konferenciája (MAFIOK), Békéscsaba, Szent István Egyetem Gazdasági Kar, 2010. augusztus 24-26. (előadás hazai konferencián)
Fintor, K.; Kaczur, S. (előadó: Fintor, K.): Vetőmozgások 3D-s szimulációjának alkalmazása a földtudományi képzésben, Matematikát, fizikát és informatikát oktatók XXXIV. konferenciája (MAFIOK), Békéscsaba, Szent István Egyetem Gazdasági Kar, 2010. augusztus 24-26. (előadás hazai konferencián)
S. Kaczur; S. Kopácsi: Practical application of coordinate and dot transformations, A GAMF Közleményei, Kecskemét, XXIII. évf., 2008, HU ISSN 1587-4400, p. 121-126 (idegen nyelvű szakcikk)
Kaczur, S.; Kopácsi, S. (előadó: Kaczur, S.): Koordináta- és ponttranszformációk alkalmazása a gyakorlatban, Felsőfokú alapképzésben matematikát, fizikát és informatikát oktatók XXXII. Konferenciája (MAFIOK), Kecskemét, Kecskeméti Főiskola, 2008. augusztus 25-27. (előadás hazai konferencián)
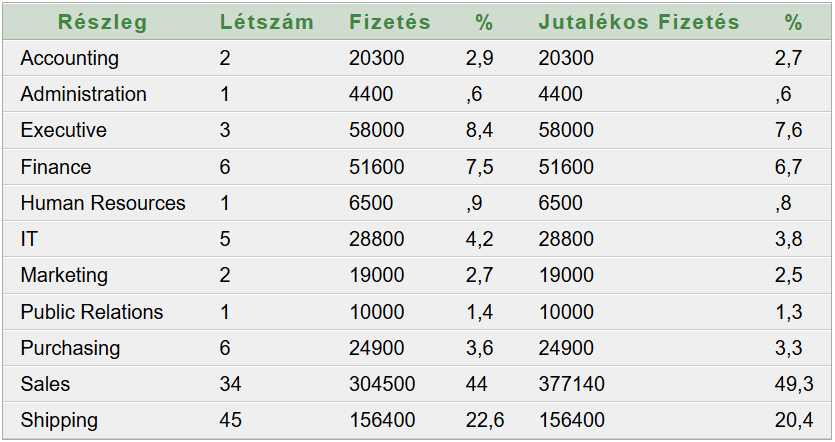
Kiss Balázs kolléga Alkalmazottak életpálya modellje – munkakör, fizetés jutalék blog bejegyzése inspirálta ezt a blog bejegyzést. Az Oracle HR sémában az értékesítési vezetők adható havi fizetése 10000 és 20000 között van, átlagfizetésük 12200. Az üzletkötők paraméterei hasonlóan: 6000, 12000, 8350. A pénznem USD. Mi lenne, ha…? Ha többféleképpen is kalkulálhatnánk jutalékokat fizetési modellek alapján. Vajon hogyan lehetne választani? Következzen kétféle fizetési modell az alkalmazottak jutalékaihoz kötődően.
Alkossunk egy fizetési modellt! Hogyan kalkuláljuk a jutalékokat?
A jutalék negyedévente kerül kifizetésre és a havi fizetés megadott százaléka. Például: Elizabeth Bates üzletkötő havi fizetése 7300, jutaléka 15%, azaz minden 3. hónapban a fizetése 8395 helyett 10585. A negyedévek első két hónapjában a cég bérköltsége 691400, az utolsó hónapjában pedig 765090. Mindez arra a 106 fő alkalmazottra vonatkozik, akik részleghez tartoznak. Nincs benne az az 1 fő, aki nincs részleghez rendelve.
Összesített megoldás
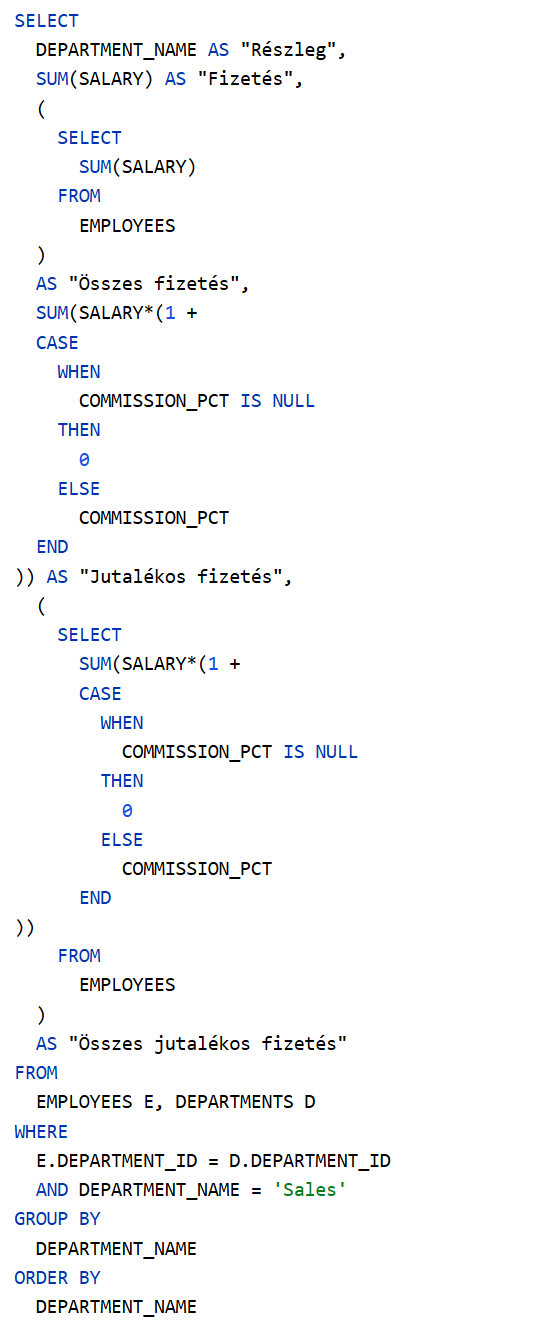
A lekérdező SQL parancs:
Eredményül ezt az eredménytáblát adja:
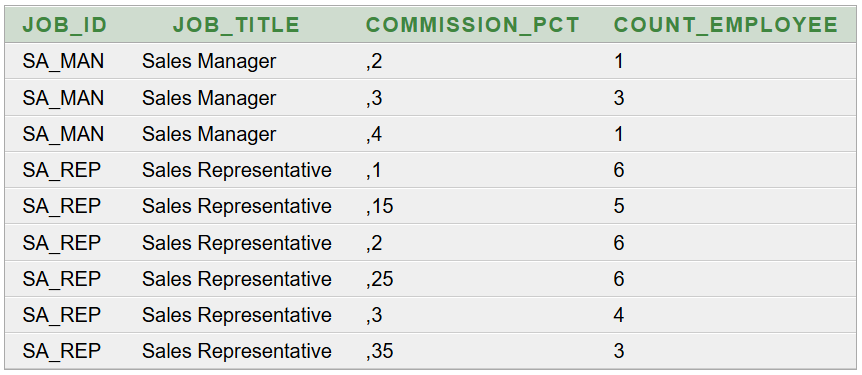
Részlegekre összesített 1. megoldás
Vegyük figyelembe azt a 106 fő alkalmazottat, akik részleghez tartoznak (a 107 fő közül). Az alábbi lekérdező SQL parancsot futtatva:
Az eredménytábla 11 rekordból áll. A százalékok a részlegre jutó bérköltség arányát fejezik ki (tényleges fizetésre és jutalékos fizetésre vonatkoztatva).
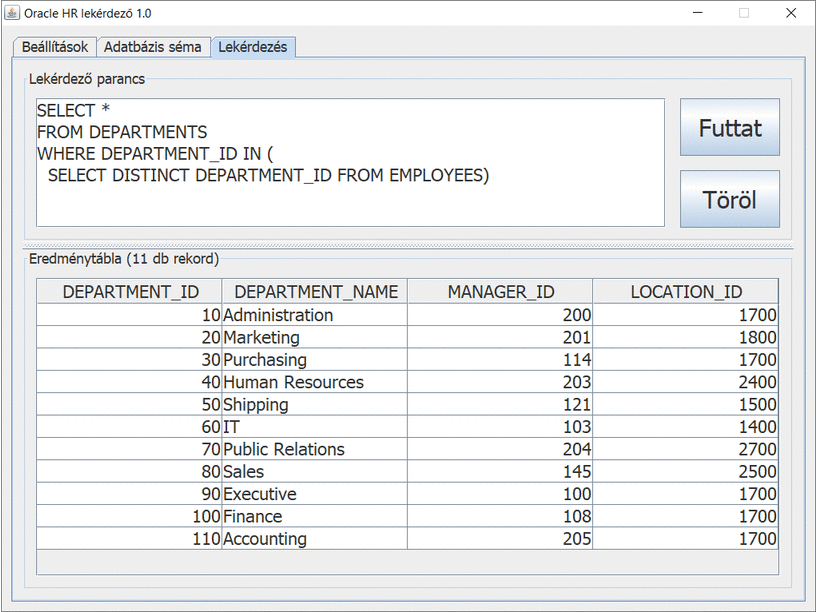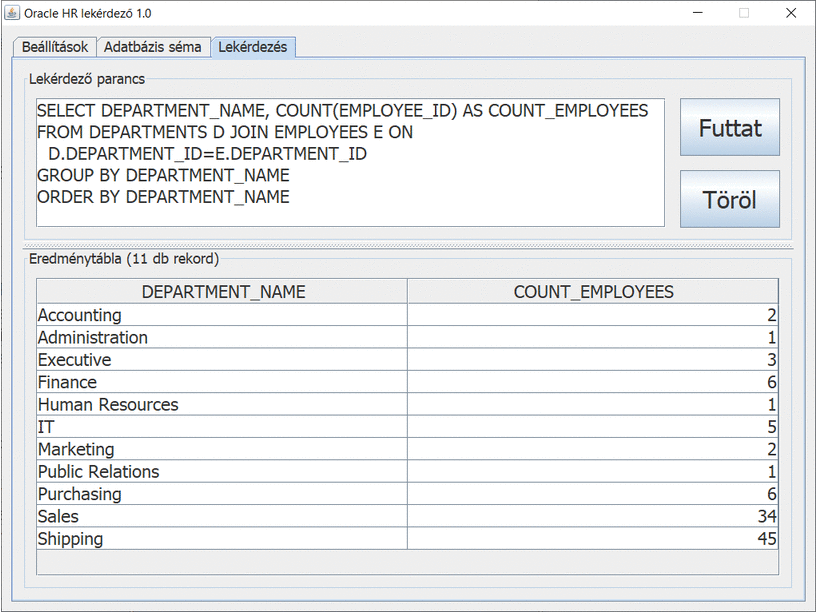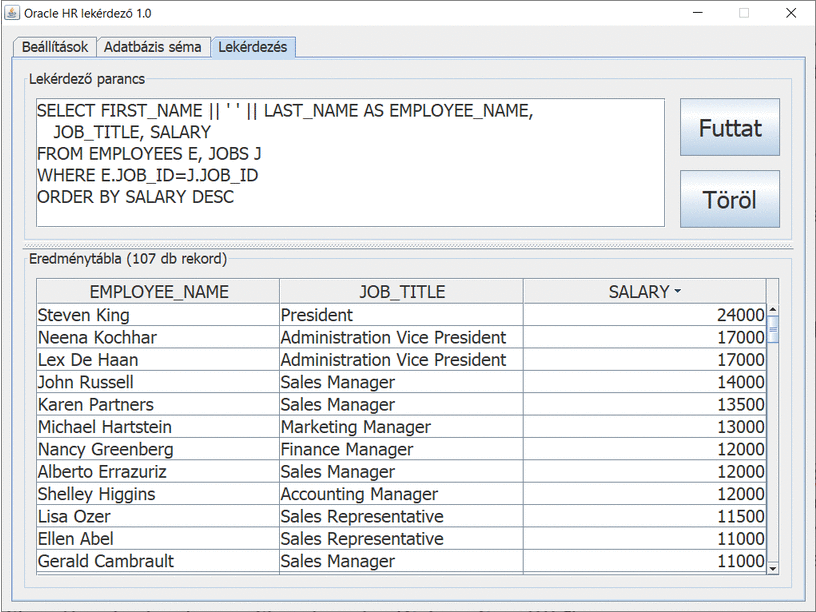
Részlegekre összesített 2. megoldás
Balázs írta, hogy a
Sales részlegben 35-en dolgoznak. Ez akkor helytálló, ha a munkakörök alapján kérdezzük le és láttuk, hogy a 35 főből értékesítési vezetőként 5 fő, üzletkötőként 30 fő dolgozik. Igen ám, de van egy olyan alkalmazott, aki nem tartozik egy részleghez sem (
DEPARTMENT_ID IS NULL), ezért kapjuk az előző eredménytábla szerint a
Sales részlegben a 34 főt. Ugyanis az azt előállító lekérdező parancs a
DEPARTMENT_ID részlegazonosító alapján kapcsolja össze a két táblát (
EMPLOYEES és
DEPARTMENTS). Ha az ő fizetését is figyelembe kell venni, akkor ez lehetséges az alábbi lekérdező paranccsal:
Az eredménytáblában az utolsó, 12. rekord tartalmazza az eddig hiányzó 1 fő alkalmazott adatait:
Az eredménytábla – az utolsó rekord kivételével – majdnem megegyezik az előzővel. A fizetési modell szerint a negyedévek első két hónapjában a cégre vonatkozó bérköltség 7000-rel növekszik és a negyedévek harmadik hónapjában pedig 8050-nel. A fizetések arányát százalékban egy tizedesjeggyel ábrázolva szinte nem vehető észre a különbség. A rekordok azonos sorrendjétől tekintsünk most el, hiszen a
UNION és az
ORDER BY alparancsok alkalmazása együtt külön történet. Aki érti, hogy mire gondolok, most biztosan kacsint egyet. 😉 Aki még nem érti, annak részletesen elmagyarázzuk Java adatbázis-kezelő tanfolyamunkon. Továbbá a százalékokat összesítve a kerekítésük miatt nem kapunk pontosan 100%-ot.
Az így kapott adatok kiegészítik a Top 5 fizetésű alkalmazottak listája blog bejegyzésben kapott adatokat. Ott nem szerepelnek az alkalmazottak részlegei, de természetesen könnyen összepárosíthatók. Másképpen: a 107 fő alkalmazottból 35 fő (32,7%) kapja a fizetések 45%-át jutalék nélkül, illetve 50,4%-t jutalékkal kalkulálva. Tehát érdemes/megéri a
Sales részlegben dolgozni. Még akár jutalék nélkül is. 🙂
A bejegyzéshez tartozó teljes Java forráskódot (ami beépítve tartalmazza a fenti SQL lekérdező parancsokat) ILIAS e-learning tananyagban tesszük elérhetővé tanfolyamaink résztvevői számára.
A feladatok a Java adatbázis-kezelő tanfolyam 13-16. óra: Konzolos kliensalkalmazás fejlesztése JDBC alapon, 1. rész alkalmához és a 33-36. óra: Grafikus kliensalkalmazás fejlesztése JDBC alapon, 1. rész alkalmához kötődnek.
Alkossunk másik fizetési modellt! Várjuk hozzászólásban a megoldás SQL parancsait.
Vajon hogyan változna az előző fizetési modell, ha a negyedévente kifizetendő jutalék számítási alapja a havi fizetés helyett a háromhavi – időszakra vonatkozó – fizetés megadott százaléka lenne? Hogyan alakulna a cég bérköltsége?
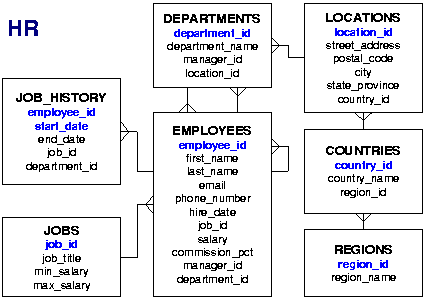
Az Oracle HR sémában 11 részleg található 107 alkalmazottal, akik 19 különböző munkakörben végzik munkájukat. Nyilvánvalóan mindenkinek a fizetése pozitív (
SALARY>0), havi, USD pénznemben. Két munkakörre jellemző, hogy tartozik hozzá jutalék (
COMMISSION_PCT), amely pozitív valós szám. A 17 többi munkakörben foglalkoztatott alkalmazott esetében az adatbázis
EMPLOYEES táblájának jutalék mezőjében
NULL található. Az Oracle HS séma:
Életpálya-modellnek tekinthető a munkakörhöz (
JOB_ID és
JOB_TITLE) tartozó adható legkisebb és legnagyobb fizetés (
MIN_SALARY,
MAX_SALARY) nyújtotta mozgástér. Minden alkalmazottra teljesül, hogy a fizetése a megadott határok között található (zárt intervallumként kezelve). Ennek ellenőrzésére használható az alábbi SQL parancs:
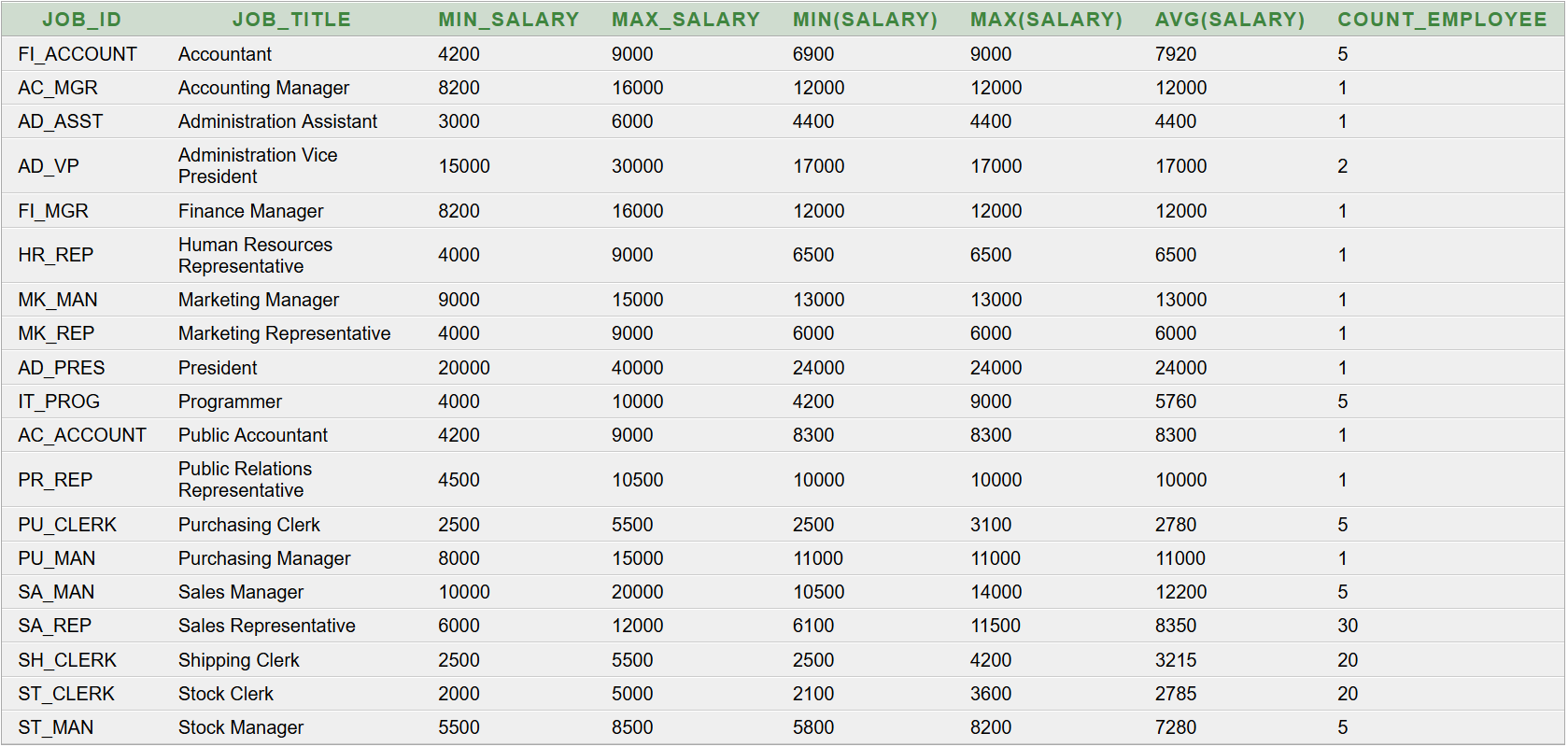
Eredménytábla:
A
MIN(SALARY) oszlopban található a valós/kapott fizetések minimuma. A mellette lévő oszlopok hasonlóan a maximumot és az átlagot mutatják. A részlegben található alkalmazottak számát az utolsó,
COUNT_EMPLOYEE oszlop tartalmazza.
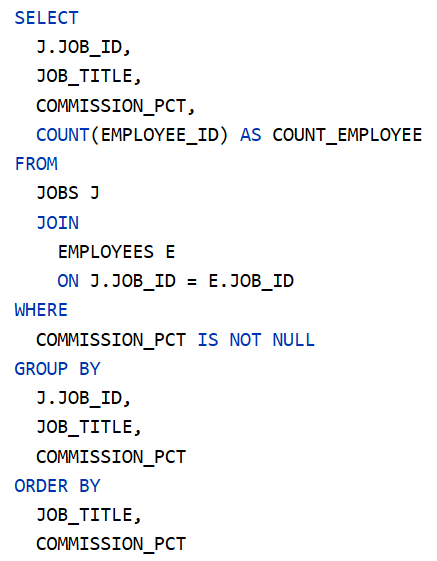
35 fő dolgozik a
Sales részlegben. Az 5 fő
Sales Manager (értékesítési vezető) jutaléka a fizetés 20%-ától 40%-áig terjedhet 10%-os lépésközzel (3-féle lehet). A 30 fő
Sales Representative (üzletkötő) jutaléka a fizetés 10%-ától 35%-áig terjedhet 5%-os lépésközzel (6-féle lehet). Ennek igazolására használható az alábbi SQL parancs:
Eredménytábla:
A bejegyzéshez tartozó teljes Java forráskódot (ami beépítve tartalmazza a fenti SQL lekérdező parancsokat) ILIAS e-learning tananyagban tesszük elérhetővé tanfolyamaink résztvevői számára.
A feladatok megoldása során nem foglalkoztam külön azzal az egy alkalmazottal, akinek nincs részlege. A feladatok a Java adatbázis-kezelő tanfolyam 13-16. óra: Konzolos kliensalkalmazás fejlesztése JDBC alapon, 1. rész alkalmához és a 33-36. óra: Grafikus kliensalkalmazás fejlesztése JDBC alapon, 1. rész alkalmához kötődnek.
A Java programozási nyelv egyik ismert GUI csomagja a swing. Ennek népszerű grafikus komponense az adatok táblázatos megjelenítését biztosító
JTable komponens. A táblázatos megjelenítéshez több beállítás is szükséges. A
JTable egy MVC komponens, így külön kezelendők a modell, nézet és a vezérlő funkcióihoz kötődő beállítások. A modell tárolja az adatokat például
DefaultTableModel típusú objektumban, amiben szétválaszthatók a fejlécben és a többi cellákban található adatok. A nézethez tartozik a betűméret, a cellák színezése, az adatok igazítása, megjelenítése, a gördítősáv. A viselkedést, a felhasználói reakciót a vezérlő határozza meg, például rendezés, görgetés, fókusz, kijelölés, oszlopok sorrendjének cseréje.
Feladat
Készítsünk olyan Java swing-es kliensprogramot, amely tetszőleges adatforrásból (XML vagy JSON a hálózatról, JDBC adatbázis kapcsolatból, ORM leképzésből származó objektumokból) képes az átvett adatok grafikus felületen való táblázatos megjelenítésére
JTable komponenssel! Építsünk arra, hogy az adatokon kívül metaadatok is rendelkezésünkre állnak! A megoldás legyen univerzális!
Képernyőképek
Modell
A táblázatos GUI komponenst kezdetben inicializálni kell, illetve a benne tárolt adatok is törölhetők, ha újrahasznosításra kerül a sor:
1
2
JTable tbEredmeny=newJTable();
tbEredmeny.setModel(newDefaultTableModel());
Ki kell nyerni a tároláshoz és a megjelenítéshez kötődő adatokat (1. lépés). A metaadatokból a
for() ciklus előállítja az
oszlopTomb-öt, és az
oszlopTipusTomb-be kerülnek az Oracle adattípusból Java objektumtípusként megfeleltetett adatok. Előbbi a fejléc feliratainak szövegeit tartalmazza, és az utóbbi befolyásolja az egyes cellákban az igazítást, illetve hatással van adott oszlop rendezésére is:
Ki kell nyerni a tároláshoz és a megjelenítéshez kötődő adatokat (2. lépés). A
while() ciklus végigjárja az eredménytábla sorait és
Object típusú tömböt állít elő az összetartozó rekord mezőiből. Ezek először generikus listába kerülnek, majd onnan kétdimenziós
Object típusú tömbbe:
Mi indokolja a tömbökből álló generikus lista (
adatLista) alkalmazását?
A
while() ciklus végrehajtása előtt nem tudjuk lekérdezni, hogy mennyi rekordot kaptunk vissza, így nem tudjuk rögtön az
adatTomb-be tenni az adatokat. A Java nyelvben a tömbök mérete fix, és a deklaráció során meg kell adni. Az eredménytábla metaadatai között megtalálható a mezők száma, ami felhasználható a kétdimenziós tömb oszlopszámaként. A generikus lista dinamikus, annyi elemből fog állni, ahány lépésben végrehajtódik a
while() ciklus. Ezután a listától lekérdezhető az elemszáma (
adatLista.size()), és ezzel megvan a kétdimenziós tömb sorainak száma, ami eddig hiányzott. Persze használhatnánk
Vector-t is a tömbökből álló generikus lista helyett (mert a
DefaultTableModel-nek van olyan túlterhelt konstruktora, ami átvenné paraméterként), de ezt inkább nem tesszük, hiszen a
Vector már régóta obsolete kollekció.
Előállítjuk a vizuális komponens mögötti adatmodellt. Öröklődéssel kiegészítjük két hasznos függvénnyel, így cellák rajzolása/renderelése és rendezése megkaphatja a szükséges adattípust (
getColumnClass()), valamint letiltható a cellák szerkeszthetősége (
isCellEditable()). Utóbbiak inkább a vezérléshez kötődnek, de modellen keresztül itt és így kell beállítani:
Végül a vizuális komponens mögötti adatmodellt kell átadni:
1
tbEredmeny.setModel(dtm);
Nézet
Adott betűtípus, betűstílus és betűméret használható a táblázat fejlécében, celláiban, illetve a betűmérettől függhet a sorok magassága:
1
2
3
4
Font betutipus=newFont("Tahoma",Font.PLAIN,18);
tbEredmeny.getTableHeader().setFont(betutipus);
tbEredmeny.setFont(betutipus);
tbEredmeny.setRowHeight(24);
Hasznos ha
JScrollPane típusú gördítősáv tartozik a táblázathoz, így dinamikusan megjeleníthető/elrejthető a függőleges/vízszintes gördítősáv:
1
spGorditosav.setViewportView(tbEredmeny);
Vezérlés
Az adatokhoz valahogyan hozzá kell jutni. Most JDBC kapcsolatot használunk és az Oracle HR sémából kérdezünk le adatokat, de a forráskód-részlet univerzális. A folyamat a következő:
Betöltjük a
driver osztályt.
Autentikációval
c kapcsolatot nyitunk az adatbázis-szerver felé.
Végrehajtjuk a lekérdező SQL parancsot.
Feldolgozzuk az eredményül kapott
ResultSet típusú
rs objektumot.
Ha engedélyezzük, akkor a megjelenő táblázat fejlécében az egyes oszlopok felirataira kattintva elérhetjük, hogy az adott oszlop típusának megfelelően növekvő vagy csökkenő sorrendbe átrendeződjenek az adatok:
1
tbEredmeny.setAutoCreateRowSorter(true);
A kivételkezelést nem részleteztük a fenti forráskódoknál, de természetesen kötelezően adott.
A bejegyzéshez tartozó teljes forráskódot ILIAS e-learning tananyagban tesszük elérhetővé tanfolyamaink résztvevői számára.
Weboldalunkon cookie-kat (sütiket) használunk, melyek célja, hogy teljesebb szolgáltatást nyújtsunk látogatóink részére. További böngészésével hozzájárul ezek használatához. ElfogadAdatkezelési szabályzat
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.

 Doktoranduszok programoznak – újratöltve
Doktoranduszok programoznak – újratöltve


 Saját doktorandusz csoporttársaimmal én is többször beszélgettem már arról –
Saját doktorandusz csoporttársaimmal én is többször beszélgettem már arról –