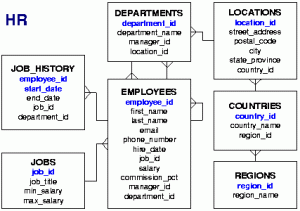
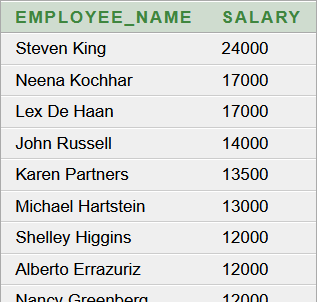
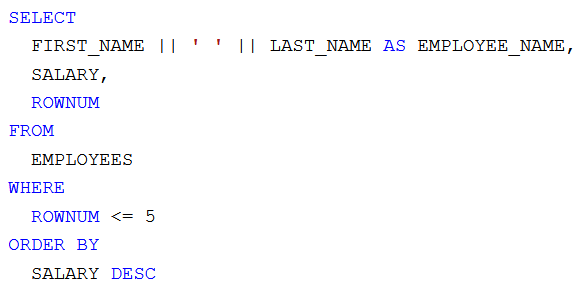
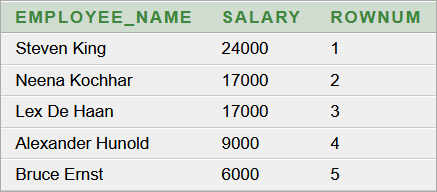
[lorem, ipsum, dolor, sit, amet, consectetur, adipiscing, elit, curabitur, quis, mauris, laoreet, lobortis, orci, eget, egestas, dui, vivamus, pretium, nunc, sit, amet, ex, dictum, rutrum, duis, sodales, augue, dui, vitae, porta, eros, auctor, non, pellentesque, vehicula, sollicitudin, scelerisque, sed, urna, massa, auctor, nec, tellus, at, iaculis, dictum, ligula, nunc, vitae, metus, quis, velit, hendrerit, finibus, aenean, et, nunc, et, sem, facilisis, sagittis, phasellus, vestibulum, accumsan, eleifend, etiam, finibus, est, fringilla, augue, imperdiet, lacinia, suspendisse, eleifend, magna, quis, sollicitudin, euismod, turpis, enim, pretium, nulla, at, vulputate, justo, sem, vel, ipsum, donec, vestibulum, risus, viverra, purus, sodales, nec, laoreet, tortor, volutpat, pellentesque, vitae, sodales, odio, morbi, tristique, vitae, justo, ac, dictum, nam, eleifend, dolor, sapien, ullamcorper, pellentesque, quam, semper, quissuspendisse, eu, aliquet, lectus, maecenas, placerat, nunc, nec, ipsum, tempor, suscipit, donec, fringilla, lacinia, aliquam, fusce, maximus, nunc, eget, nibh, dignissim, id, aliquam, ex, fringilla, donec, eget, blandit, tortor, nunc, at, ornare, lectus, non, varius, augue, donec, cursus, velit, ligula, non, volutpat, tellus, euismod, eu, mauris, dictum, nisl, consequat, nisl, dapibus, placerat, maecenas, in, purus, leo, praesent, imperdiet, aliquet, porttitor, nunc, tempus, maximus, enim, integer, imperdiet, luctus, lorem, eget, luctus, nullam, et, sapien, fringilla, vestibulum, lectus, at, porttitor, odio, sed, cursus, mollis, ante, ac, volutpat, est, facilisis, nonlorem, ipsum, dolor, sit, amet, consectetur, adipiscing, elit, vestibulum, id, posuere, tellus, quisque, ornare, sem, ac, maximus, porttitor, eros, dui, porta, sem, ornare, vulputate, mi, leo, vel, nunc, donec, leo, ex, fringilla, cursus, dui, at, congue, euismod, velit, nunc, viverra, lectus, vel, nunc, tempus, viverra, suspendisse, potenti, integer, vel, purus, commodo, rutrum, lectus, nec, pharetra, sem, proin, blandit, tincidunt, turpis, in, pulvinar, aliquam, malesuada, tellus, id, dui, ullamcorper, pellentesque, donec, vel, urna, felismorbi, blandit, ipsum, eget, tellus, efficitur, ac, pulvinar, nunc, porttitor, quisque, nec, posuere, elit, ac, sollicitudin, sem, vestibulum, faucibus, ante, lectus, vel, congue, erat, molestie, sed, maecenas, ac, leo, porttitor, congue, felis, sit, amet, dignissim, nibh, quisque, porttitor, neque, maximus, est, scelerisque, nec, gravida, orci, eleifend, aenean, ac, magna, ut, dolor, aliquet, fermentum, vel, nec, risus, phasellus, in, ullamcorper, mauris, phasellus, semper, blandit, bibendum, cras, vitae, purus, fermentum, diam, dapibus, dictum, curabitur, sapien, neque, rutrum, in, dapibus, eu, ornare, at, anteinteger, facilisis, libero, convallis, pellentesque, gravida, velit, odio, interdum, nisi, vel, ultricies, nisl, sapien, et, eros, pellentesque, habitant, morbi, tristique, senectus, et, netus, et, malesuada, fames, ac, turpis, egestas, morbi, nec, ante, at, ante, blandit, fringilla, eu, sed, nisi, suspendisse, potenti, maecenas, neque, lacus, laoreet, nec, lacinia, efficitur, suscipit, at, est, mauris, lacinia, fringilla, ligula, sit, amet, blandit, nisl, ullamcorper, sed, nulla, et, velit, laoreet, egestas, sapien, vitae, elementum, leo, suspendisse, laoreet, nibh, neque, et, convallis, dolor, vulputate, idfusce, at, elit, a, libero, ullamcorper, interdum, vitae, bibendum, urna, proin, porta, est, lorem, eget, accumsan, nibh, placerat, ut, aenean, scelerisque, lectus, rutrum, efficitur, mollis, elit, eros, dapibus, velit, eu, lobortis, ipsum, felis, quis, dui, cras, quis, faucibus, eros, eget, scelerisque, ligula, proin, tempor, felis, quis, tellus, ornare, sodales, curabitur, quam, sapien, venenatis, nec, diam, in, molestie, euismod, arcu, morbi, malesuada, sodales, metus, vitae, ornare, nisl, eleifend, nec, nulla, nec, metus, sed, diam, vestibulum, commodo, vel, vitae, lectus, suspendisse, quis, quam, eu, nibh, suscipit, faucibus, quis, ut, orcicras, quis, mi, sit, amet, ante, fermentum, consectetur, aliquam, euismod, libero, vitae, euismod, dapibus, class, aptent, taciti, sociosqu, ad, litora, torquent, per, conubia, nostra, per, inceptos, himenaeos, morbi, auctor, in, mi, vitae, egestas, aenean, justo, nisl, consectetur, quis, dui, cursus, consectetur, commodo, lacus, in, scelerisque, erat, ac, ligula, aliquet, ultrices, aliquam, rutrum, ut, tortor, sed, pellentesque, aliquam, semper, felis, sed, finibus, scelerisque, neque, odio, consectetur, odio, eget, imperdiet, quam, quam, ut, arcu, maecenas, non, arcu, tempus, ornare, quam, vel, fringilla, turpis, vivamus, rhoncus, velit, sed, mauris, pretium, pharetra, mauris, tempor, leo, quis, tristique, ullamcorper, mauris, mi, aliquet, dui, sed, ullamcorper, risus, nunc, quis, metusdonec, in, laoreet, lectus, ut, sit, amet, mattis, diam, maecenas, et, mauris, eget, lacus, mollis, sodales, pellentesque, porttitor, venenatis, accumsan, in, a, aliquet, tortor, donec, condimentum, lectus, sem, quis, ornare, magna, dapibus, ac, mauris, maximus, dolor, in, porttitor, pulvinar, cras, ut, magna, eros, nullam, eu, dolor, eget, purus, aliquam, bibendum, vel, nec, erat, duis, augue, justo, ornare, non, urna, id, elementum, pulvinar, arcu, donec, placerat, quam, lorem, pulvinar, laoreet, justo, hendrerit, vitae, suspendisse, porta, accumsan, leo, mauris, suscipit, urna, ac, erat, convallis, auctorquisque, sollicitudin, elit, odio, mauris, tempor, eu, lorem, nec, rhoncus, aliquam, in, feugiat, tellus, maecenas, elementum, euismod, ex, in, maximus, scelerisque, viverra, nam, vel, placerat, quam, sit, amet, eleifend, nisi, cras, porta, tincidunt, malesuada, ut, congue, porta, pellentesque, donec, porttitor, elit, ac, tempor, malesuada, etiam, ultricies, laoreet, ante, vitae, interdum, felis, rhoncus, eu, morbi, dignissim, consequat, sempernam, luctus, molestie, turpis, vel, bibendum, ante, lobortis, eget, orci, varius, natoque, penatibus, et, magnis, dis, parturient, montes, nascetur, ridiculus, mus, sed, cursus, urna, nisl, molestie, faucibus, libero, pulvinar, nec, nulla, facilisi, integer, lorem, odio, suscipit, vel, risus, eget, tempor, vulputate, nulla, morbi, a, posuere, arcu, praesent, et, arcu, dolor, sed, placerat, eros, vel, lacus, interdum, viverra, ut, pulvinar, dui, ac, enim, rhoncus, hendrerit]






 Vajon hogyan kerül elő a Rómeó és Júlia az
Vajon hogyan kerül elő a Rómeó és Júlia az