A
A 















![]() A Java programozási nyelv egyik ismert GUI csomagja a swing. Ennek népszerű grafikus komponense az adatok táblázatos megjelenítését biztosító
JTable komponens. A táblázatos megjelenítéshez több beállítás is szükséges. A
JTable egy MVC komponens, így külön kezelendők a modell, nézet és a vezérlő funkcióihoz kötődő beállítások. A modell tárolja az adatokat például
DefaultTableModel típusú objektumban, amiben szétválaszthatók a fejlécben és a többi cellákban található adatok. A nézethez tartozik a betűméret, a cellák színezése, az adatok igazítása, megjelenítése, a gördítősáv. A viselkedést, a felhasználói reakciót a vezérlő határozza meg, például rendezés, görgetés, fókusz, kijelölés, oszlopok sorrendjének cseréje.
A Java programozási nyelv egyik ismert GUI csomagja a swing. Ennek népszerű grafikus komponense az adatok táblázatos megjelenítését biztosító
JTable komponens. A táblázatos megjelenítéshez több beállítás is szükséges. A
JTable egy MVC komponens, így külön kezelendők a modell, nézet és a vezérlő funkcióihoz kötődő beállítások. A modell tárolja az adatokat például
DefaultTableModel típusú objektumban, amiben szétválaszthatók a fejlécben és a többi cellákban található adatok. A nézethez tartozik a betűméret, a cellák színezése, az adatok igazítása, megjelenítése, a gördítősáv. A viselkedést, a felhasználói reakciót a vezérlő határozza meg, például rendezés, görgetés, fókusz, kijelölés, oszlopok sorrendjének cseréje.
Feladat
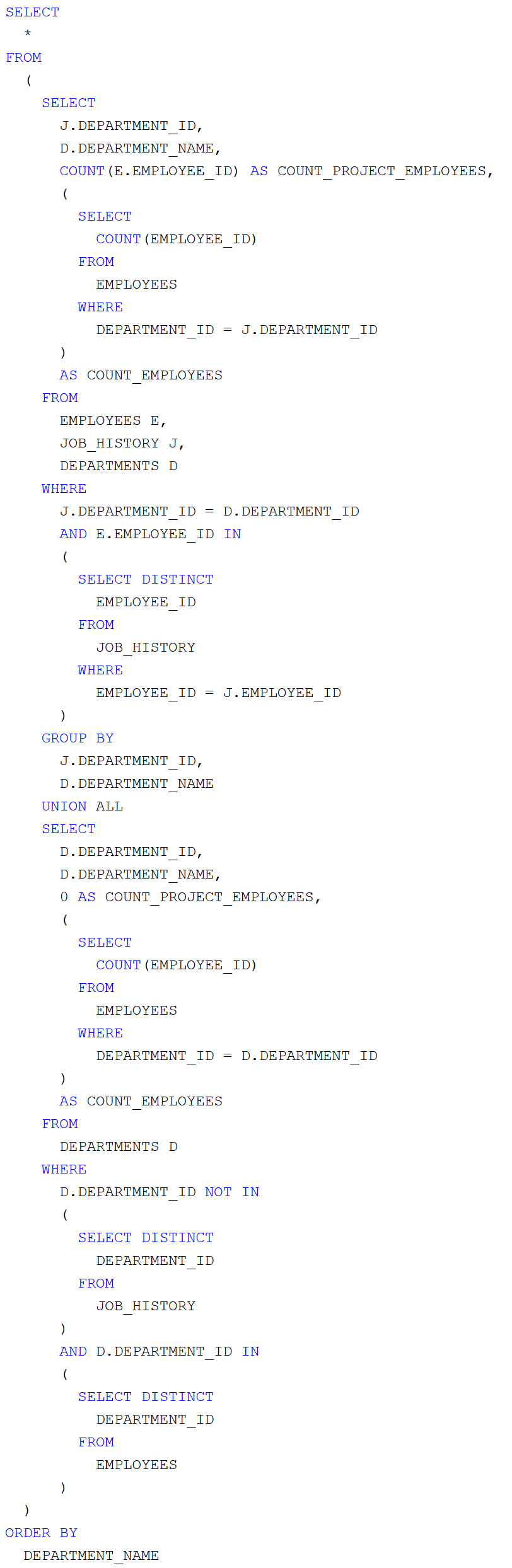
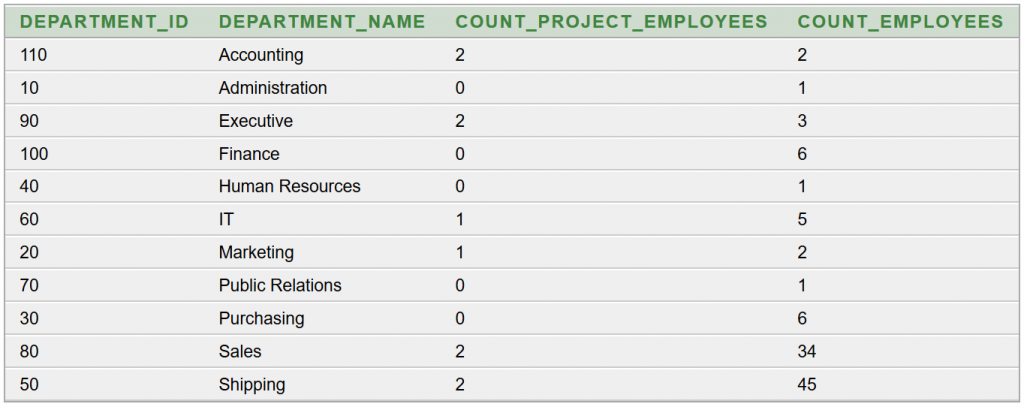
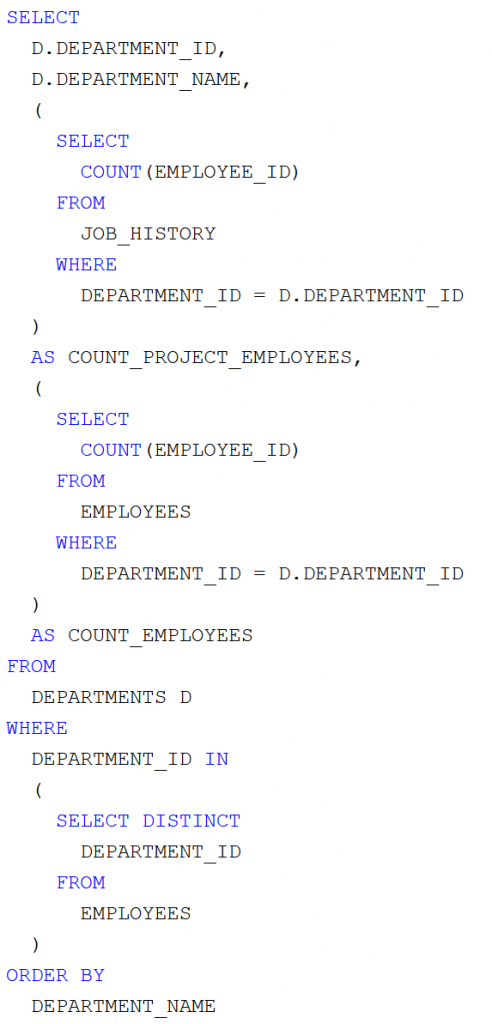
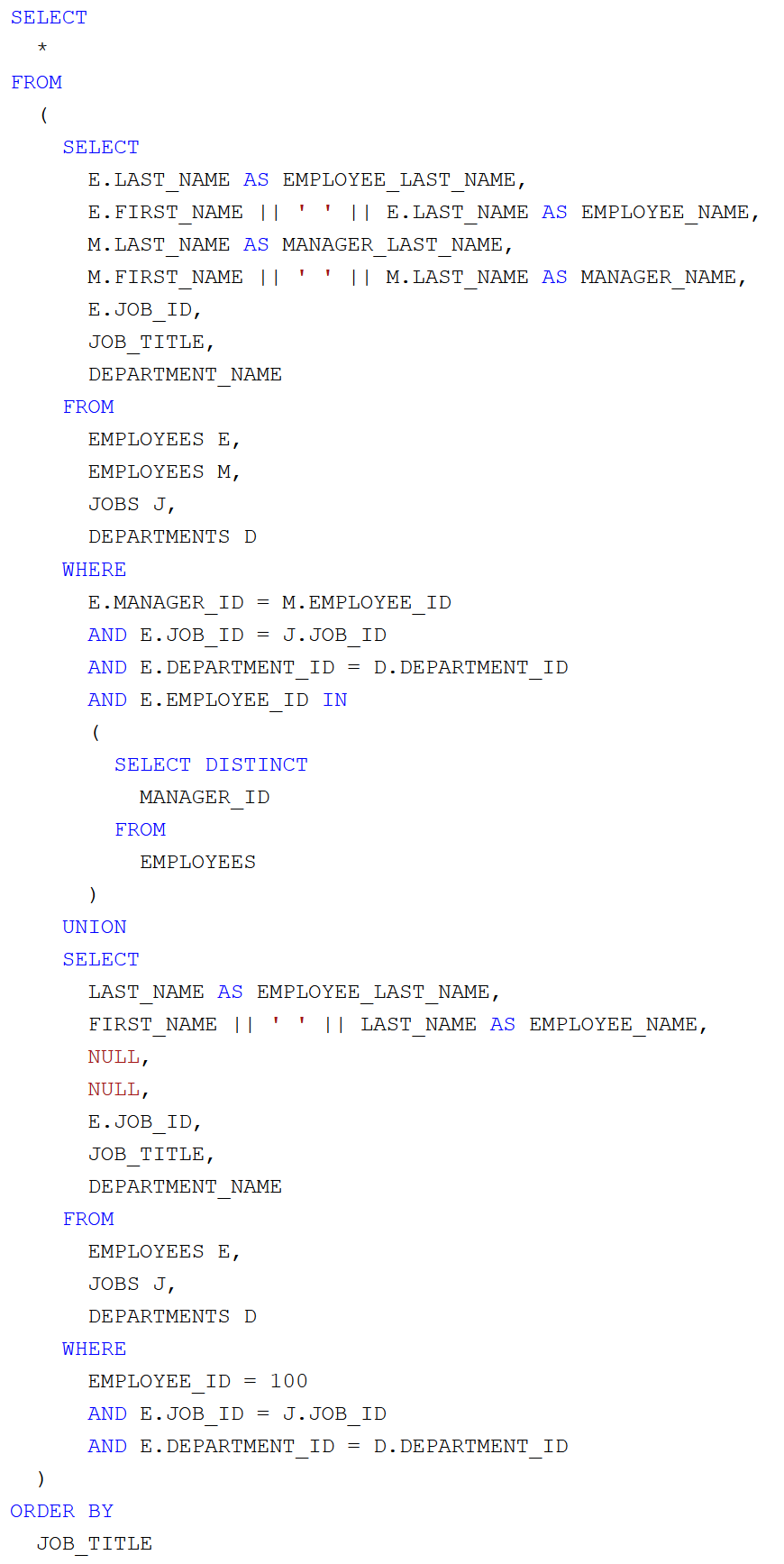
Készítsünk olyan Java swing-es kliensprogramot, amely tetszőleges adatforrásból (XML vagy JSON a hálózatról, JDBC adatbázis kapcsolatból, ORM leképzésből származó objektumokból) képes az átvett adatok grafikus felületen való táblázatos megjelenítésére JTable komponenssel! Építsünk arra, hogy az adatokon kívül metaadatok is rendelkezésünkre állnak! A megoldás legyen univerzális!
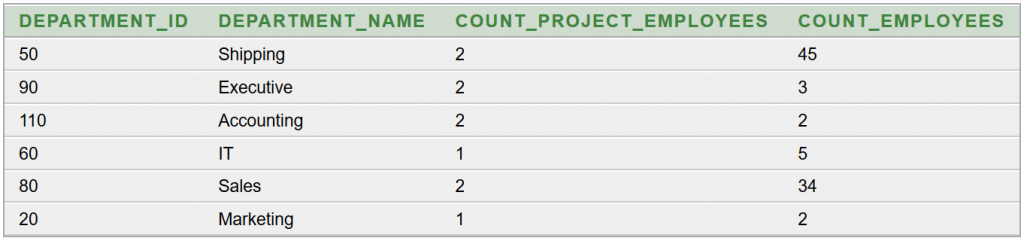
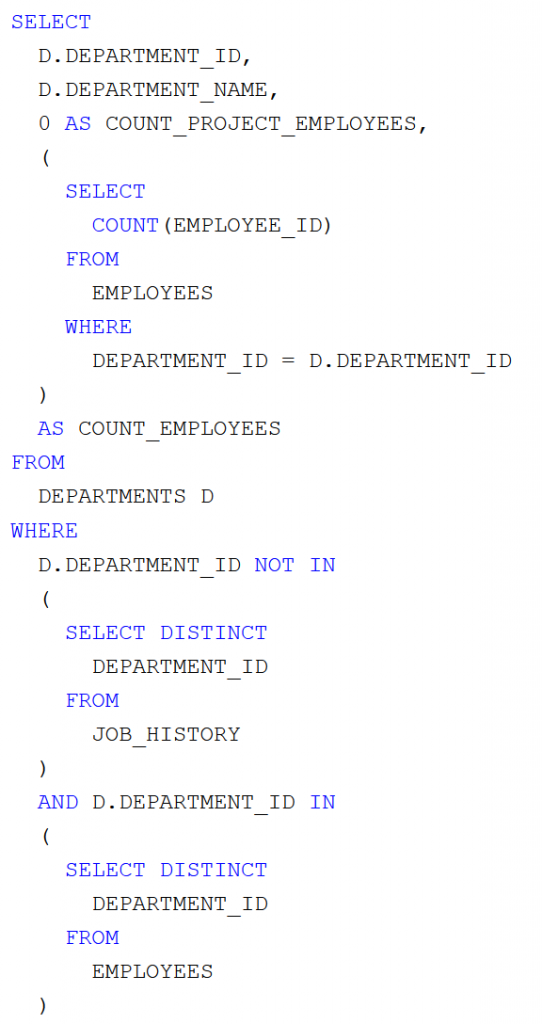
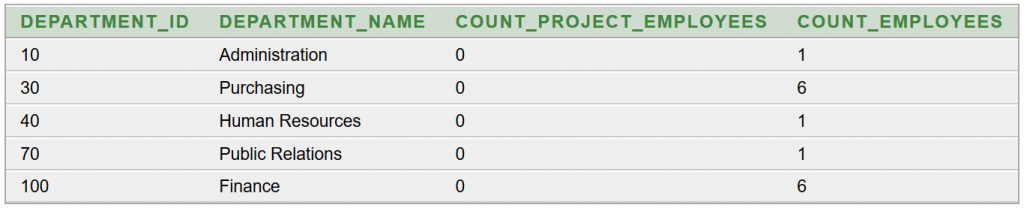
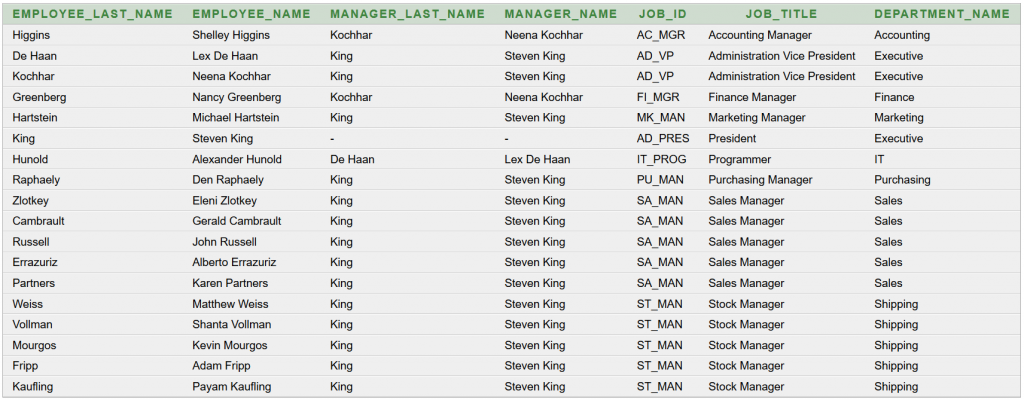
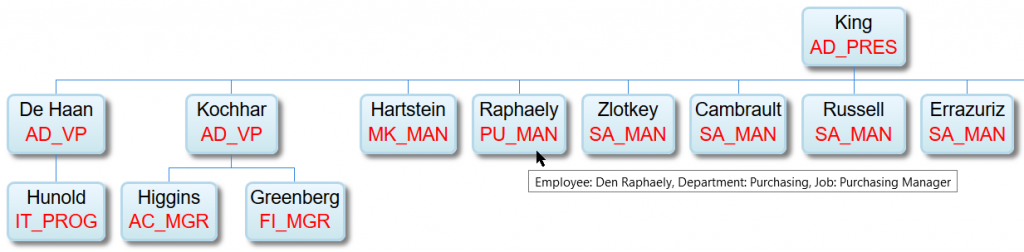
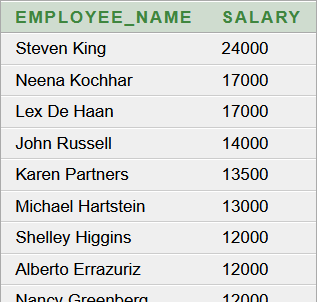
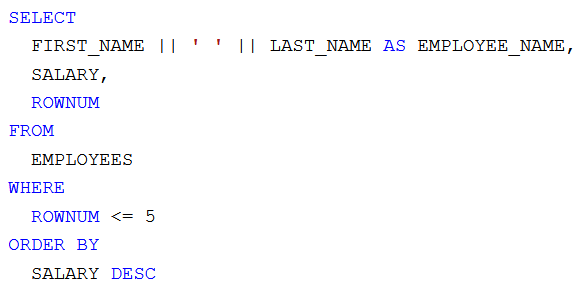
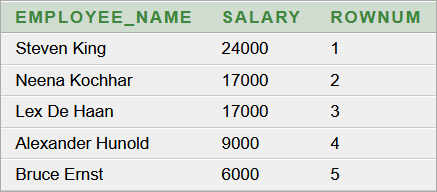
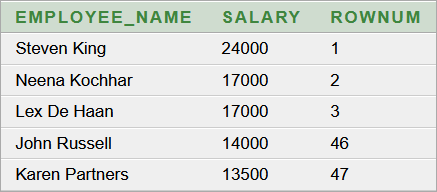
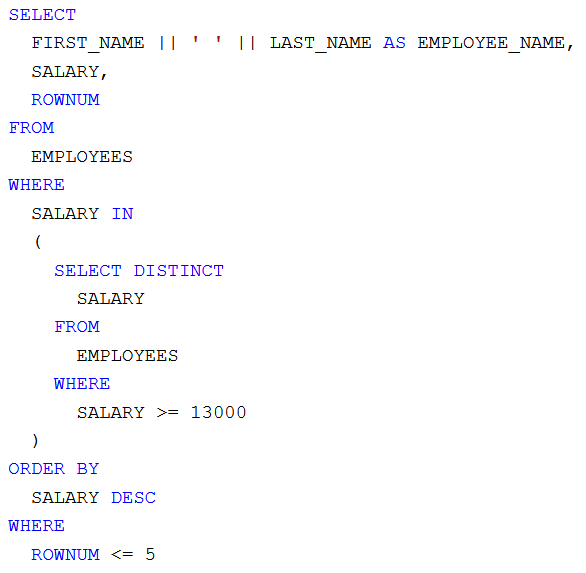
Képernyőképek
Modell
A táblázatos GUI komponenst kezdetben inicializálni kell, illetve a benne tárolt adatok is törölhetők, ha újrahasznosításra kerül a sor:
|
1 2 |
JTable tbEredmeny=new JTable(); tbEredmeny.setModel(new DefaultTableModel()); |
Ki kell nyerni a tároláshoz és a megjelenítéshez kötődő adatokat (1. lépés). A metaadatokból a for() ciklus előállítja az oszlopTomb-öt, és az oszlopTipusTomb-be kerülnek az Oracle adattípusból Java objektumtípusként megfeleltetett adatok. Előbbi a fejléc feliratainak szövegeit tartalmazza, és az utóbbi befolyásolja az egyes cellákban az igazítást, illetve hatással van adott oszlop rendezésére is:
|
1 2 3 4 5 6 7 |
ResultSetMetaData rsmd=rs.getMetaData(); String[] oszlopTomb=new String[rsmd.getColumnCount()]; Class[] oszlopTipusTomb=new Class[oszlopTomb.length]; for(int i=0; i<oszlopTomb.length; i++) { oszlopTomb[i]=rsmd.getColumnName(i+1); oszlopTipusTomb[i]=Class.forName(rsmd.getColumnClassName(i+1)); } |
Ki kell nyerni a tároláshoz és a megjelenítéshez kötődő adatokat (2. lépés). A while() ciklus végigjárja az eredménytábla sorait és Object típusú tömböt állít elő az összetartozó rekord mezőiből. Ezek először generikus listába kerülnek, majd onnan kétdimenziós Object típusú tömbbe:
|
1 2 3 4 5 6 7 8 9 10 |
ArrayList<Object[]> adatLista=new ArrayList<>(); while(rs.next()) { Object[] rekord=new Object[oszlopTomb.length]; for(int i=0; i<oszlopTomb.length; i++) rekord[i]=rs.getObject(i+1); adatLista.add(rekord); } Object[][] adatTomb=new Object[adatLista.size()][oszlopTomb.length]; for(int i=0; i<adatTomb.length; i++) adatTomb[i]=adatLista.get(i); |
Mi indokolja a tömbökből álló generikus lista ( adatLista) alkalmazását?
Előállítjuk a vizuális komponens mögötti adatmodellt. Öröklődéssel kiegészítjük két hasznos függvénnyel, így cellák rajzolása/renderelése és rendezése megkaphatja a szükséges adattípust ( getColumnClass()), valamint letiltható a cellák szerkeszthetősége ( isCellEditable()). Utóbbiak inkább a vezérléshez kötődnek, de modellen keresztül itt és így kell beállítani:
|
1 2 3 4 5 6 7 8 9 10 11 |
DefaultTableModel dtm=new DefaultTableModel(adatTomb, oszlopTomb) { Class[] types=oszlopTipusTomb; @Override public Class getColumnClass(int columnIndex) { return types [columnIndex]; } @Override public boolean isCellEditable(int row, int column) { return false; } }; |
Végül a vizuális komponens mögötti adatmodellt kell átadni:
|
1 |
tbEredmeny.setModel(dtm); |
Nézet
Adott betűtípus, betűstílus és betűméret használható a táblázat fejlécében, celláiban, illetve a betűmérettől függhet a sorok magassága:
|
1 2 3 4 |
Font betutipus=new Font("Tahoma", Font.PLAIN, 18); tbEredmeny.getTableHeader().setFont(betutipus); tbEredmeny.setFont(betutipus); tbEredmeny.setRowHeight(24); |
Hasznos ha JScrollPane típusú gördítősáv tartozik a táblázathoz, így dinamikusan megjeleníthető/elrejthető a függőleges/vízszintes gördítősáv:
|
1 |
spGorditosav.setViewportView(tbEredmeny); |
Vezérlés
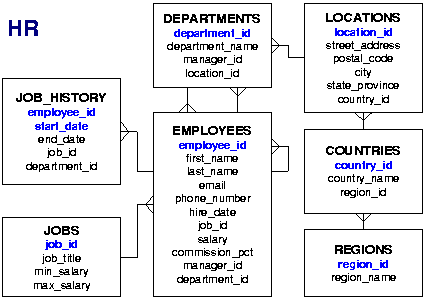
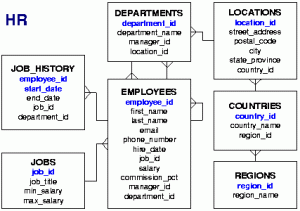
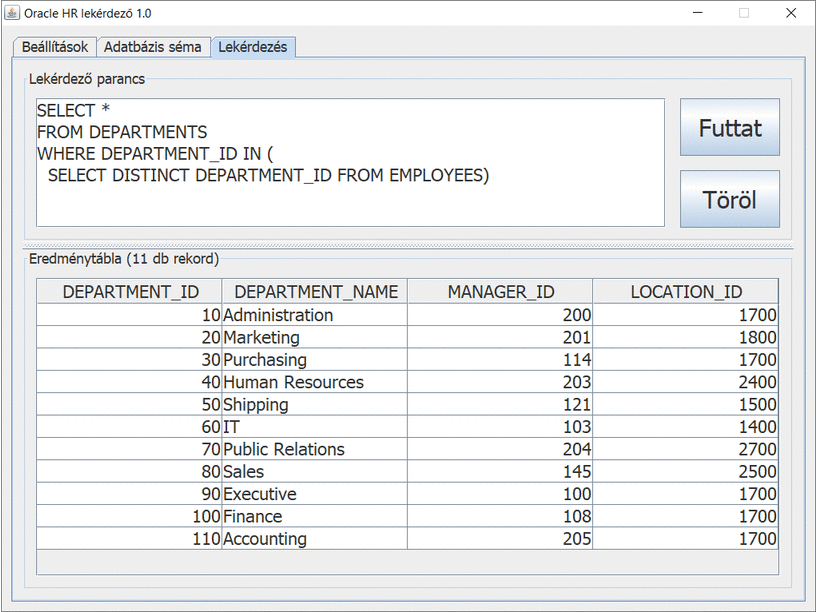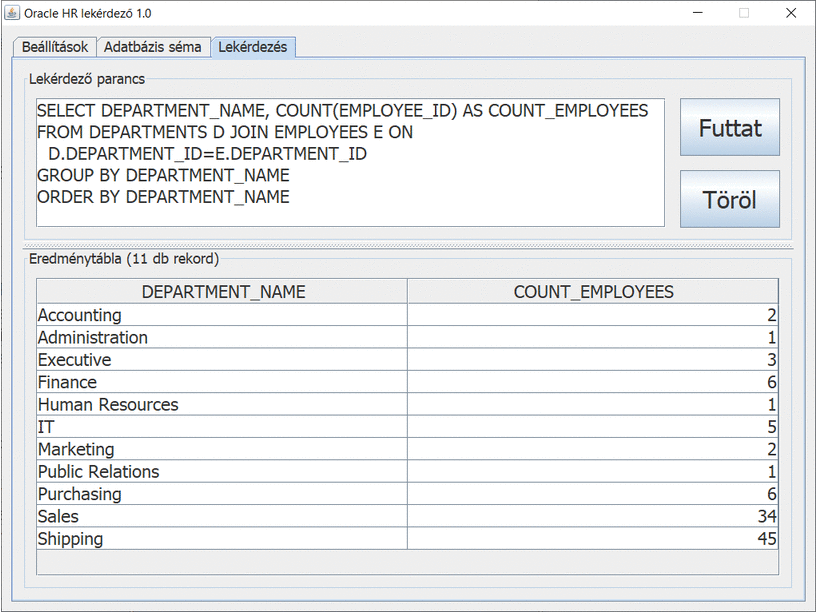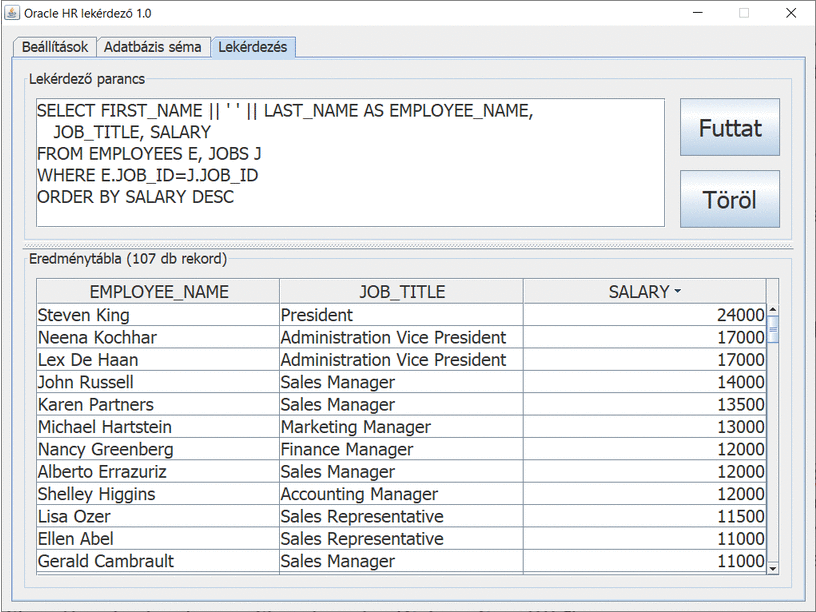
Az adatokhoz valahogyan hozzá kell jutni. Most JDBC kapcsolatot használunk és az Oracle HR sémából kérdezünk le adatokat, de a forráskód-részlet univerzális. A folyamat a következő:
- Betöltjük a driver osztályt.
- Autentikációval c kapcsolatot nyitunk az adatbázis-szerver felé.
- Végrehajtjuk a lekérdező SQL parancsot.
- Feldolgozzuk az eredményül kapott ResultSet típusú rs objektumot.
- Végül lezárjuk a c hálózati kapcsolatot.
|
1 2 3 4 5 |
Class.forName(driver); Connection c=DriverManager.getConnection(url, user, password); ResultSet rs=c.createStatement().executeQuery(sql); //... c.close(); |
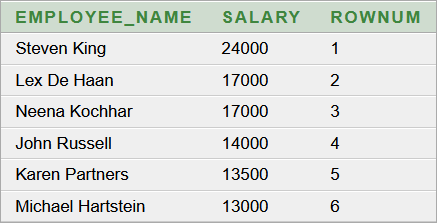
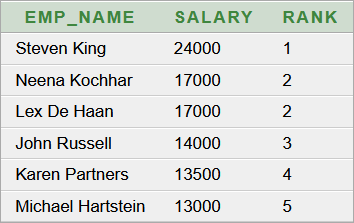
Ha engedélyezzük, akkor a megjelenő táblázat fejlécében az egyes oszlopok felirataira kattintva elérhetjük, hogy az adott oszlop típusának megfelelően növekvő vagy csökkenő sorrendbe átrendeződjenek az adatok:
|
1 |
tbEredmeny.setAutoCreateRowSorter(true); |
A kivételkezelést nem részleteztük a fenti forráskódoknál, de természetesen kötelezően adott.
A bejegyzéshez tartozó teljes forráskódot ILIAS e-learning tananyagban tesszük elérhetővé tanfolyamaink résztvevői számára.
A feladat a Java SE szoftverfejlesztő tanfolyam 45-52. óra: Adatbázis-kezelés JDBC alapon, illetve Java adatbázis-kezelő tanfolyam 9-12. óra: Oracle HR séma elemzése, 33-36. óra: Grafikus kliensalkalmazás fejlesztése JDBC alapon, 2. rész alkalmaihoz kapcsolódik.