A
A 














 Saját doktorandusz csoporttársaimmal többször beszélgettünk már arról, hogyan tudnák/tudják használni a programozás eszköztárát, módszereit, lehetőségeit saját kutatási munkájukban, beépítve a kutatási folyamat egyes lépéseibe, illetve disszertációjuk elkészítésébe.
Saját doktorandusz csoporttársaimmal többször beszélgettünk már arról, hogyan tudnák/tudják használni a programozás eszköztárát, módszereit, lehetőségeit saját kutatási munkájukban, beépítve a kutatási folyamat egyes lépéseibe, illetve disszertációjuk elkészítésébe.
Mivel a 10 fős csoportban mindenkinek más az alapvégzettsége, így szoftverfejlesztéshez, programozáshoz közös szókincs és terminológia haladó szinten természetesen nincs, viszont közös bennünk, hogy mindannyian alkotunk különféle modelleket és elemzünk adatokat.
Különféle modelleket alkotunk
- a mérnökök, fizikusok, geográfusok, biológusok többféle kísérletet végeznek el, szimulációkat terveznek és futtatnak, mérőeszközöket és műszereket használnak,
- az informatikusok különböző matematikai eszközöket alkalmazva objektumorientált – vagy másféle – modellezést végeznek, szoftvereket terveznek, javítanak, újraírnak.
Adatokat is elemzünk, ki-ki előképzettségének megfelelően
- kérdőívező szoftverekből exportálva valamit,
- Excel munkalapokon, függvényekkel, adatbázis-kezelő funkciókkal, kimutatásokkal (Pivot táblák),
- különböző fájlformátumokkal (CSV, XML, JSON, egyedi) dolgozunk és konvertálunk A-ból B-be,
- távoli adatbázisokhoz, felhőbeli adattárházakhoz csatlakozunk, lekérdezünk és kapunk valamilyen – többnyire szabványos – adathalmazt,
- matematikai, statisztikai szoftvereket használunk, például: MATLAB, Derive, Maple, SPSS.
Önszerveződően összeállítottunk egy olyan két részből álló tematikát, ami mindannyiunk számára hasznos. A 64 óra két 32 órás modulból áll: Java programozás és SPSS programrendszer.
Java programozás modul
- 1-8. óra: Objektumorientált modellezés, MVC rétegek, algoritmus- és eseményvezérelt programozás
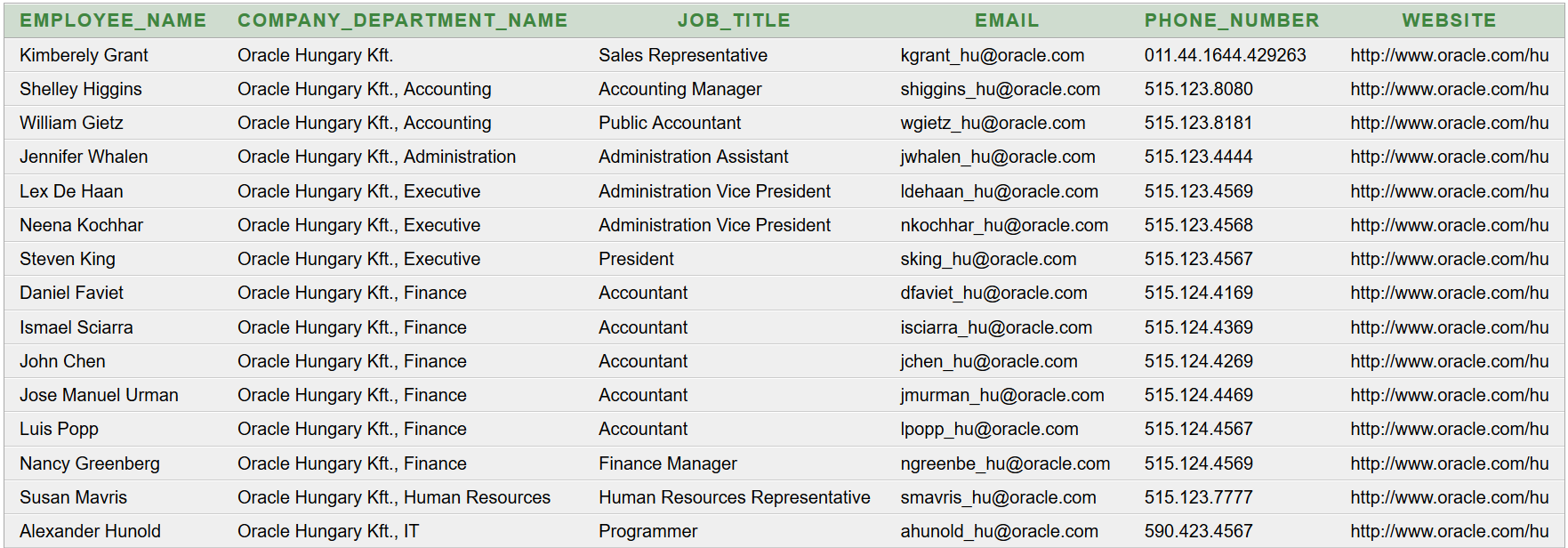
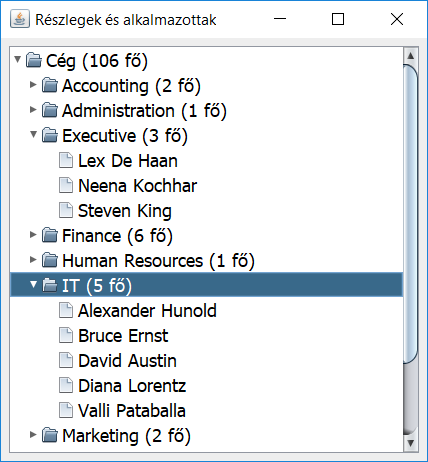
- 9-16. óra: Fájlkezelés és szövegfeldolgozás (XLS, CSV, XML, JSON formátumú adatok írása, olvasása, feldolgozása)
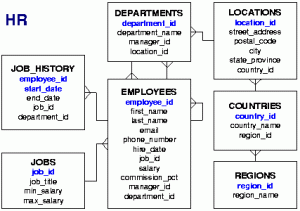
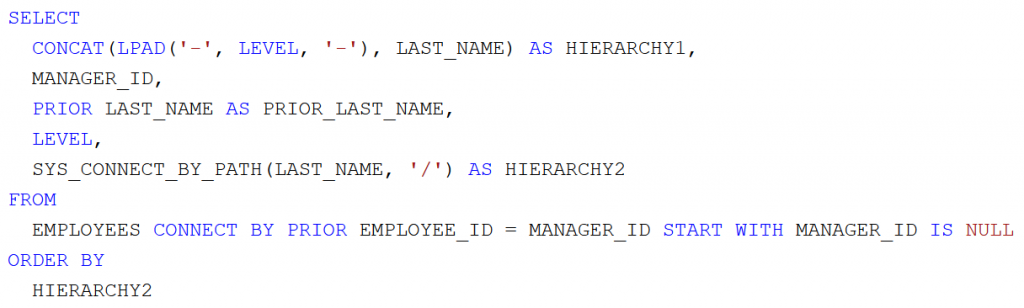
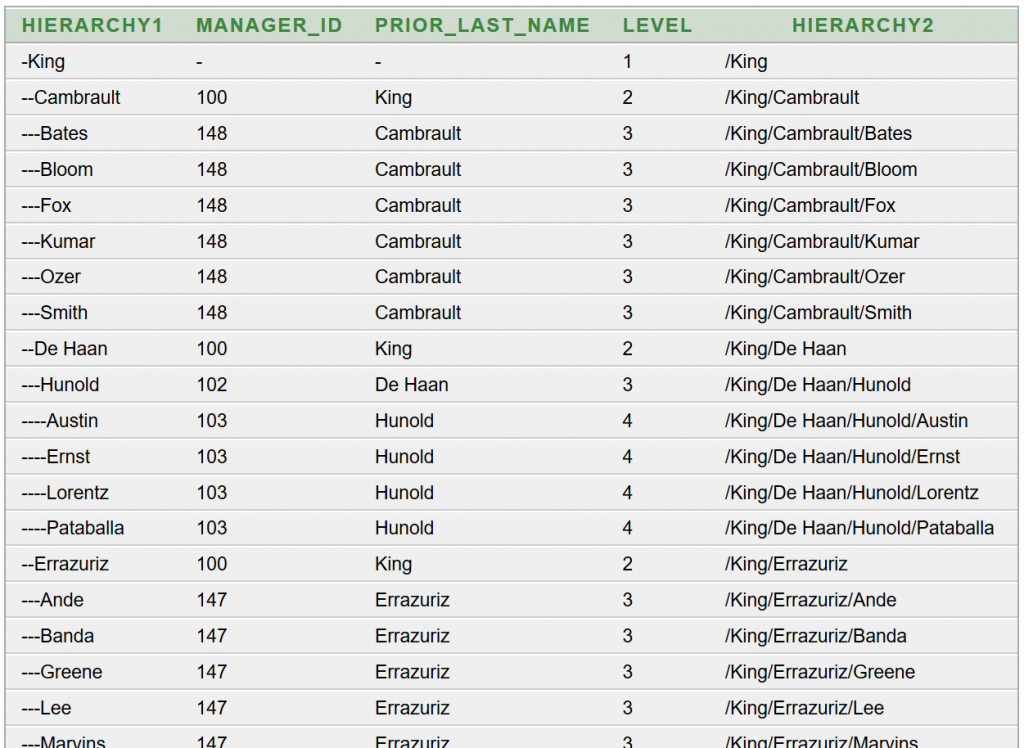
- 17-24. óra: Adatbázis-kezelés JDBC alapon (SQL parancsok, CRUD műveletek, hierarchikus lekérdezések)
- 25-32. óra: Komplex adatfeldolgozási feladatok megoldása programozási tételek használatával
SPSS programrendszer modul
- 1-8. óra: Bevezetés az SPSS-be, interakciós eszközök, adatmátrix, menük: Transform, Analyze, szkriptek futtatása
- 9-16. óra: Alapstatisztikák kérése, kereszttáblázatok készítése, hipotéziselmélethez kötődő funkciók, normalitásvizsgálat, minták összehasonlítása t-próbával
- 17-24. óra: Regresszió-analízis: lineáris, nemlineáris, többváltozós; Idősorok elemzése: szűrés, periodogram, trendelemzés
- 25-32. óra: Mesterséges neuronhálózatok: matematikai modell és működése
Mivel mindenki doktorandusz a csoportban, így a különböző MSc-s alapvégzettsége ellenére mindannyiunknak vannak strukturális programozáshoz kötődő alapismeretei, valamint adatok elemzéséhez szükséges elméleti matematikai/statisztikai alapjai. Az én részem a 32 órás Java programozás modul, ami 2018.10.28-án kezdődött és 2018.12.09-ig fog tartani hétvégi napokon. Ez nagyban lefedi a Java SE szoftverfejlesztő tanfolyamunk tematikáját és kapcsolódik a Java EE szoftverfejlesztő tanfolyamunk és a Java adatbázis-kezelő tanfolyamunk tematikájához is.
A koncepciót once-in-a-lifetime jelleggel dolgoztuk ki azzal a fő szándékkal, hogy hatékonyabban működjünk együtt a jövőben.