Az adatok strukturális és könnyen értelmezhető formában való megjelenítése egy szoftver felhasználói felületén átgondolt tervezést igényel. Az adatokhoz hozzá kell jutni, ki kell választani a megfelelő grafikus komponenst, a mögötte lévő adatmodellt, össze kell ezeket kötni. Gyakran előforduló feladat, hogy táblázatosan is ábrázolható adatokból – felhasználva az adatok közötti összefüggéseket és kapcsolatokat – csoportosítva jelenítsünk meg hierarchikusan, fa struktúrában, kinyitható-becsukható formában, ahogyan ezt a felhasználók jól ismerik a fájl- és menürendszereket használva.
Az adatok strukturális és könnyen értelmezhető formában való megjelenítése egy szoftver felhasználói felületén átgondolt tervezést igényel. Az adatokhoz hozzá kell jutni, ki kell választani a megfelelő grafikus komponenst, a mögötte lévő adatmodellt, össze kell ezeket kötni. Gyakran előforduló feladat, hogy táblázatosan is ábrázolható adatokból – felhasználva az adatok közötti összefüggéseket és kapcsolatokat – csoportosítva jelenítsünk meg hierarchikusan, fa struktúrában, kinyitható-becsukható formában, ahogyan ezt a felhasználók jól ismerik a fájl- és menürendszereket használva.
Fát építünk kétféleképpen
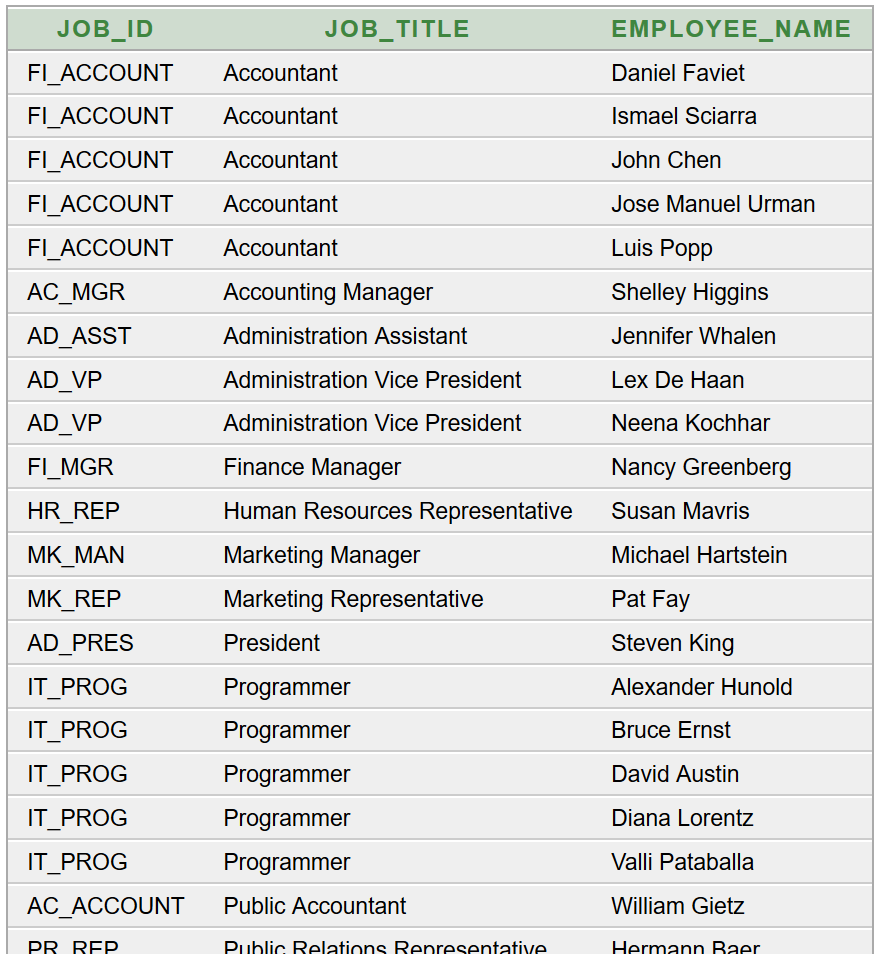
Adatbázisból, az Oracle HR sémából lekérdezünk két összetartozó nevet: részleg és alkalmazott. A lekérdezés során figyelünk a megfelelő sorrendre, ami a későbbi feldolgozást megkönnyíti. Adatainkat részlegnév szerint növekvő, azon belül alkalmazott neve szerint is növekvő – ábécé szerinti – sorrendbe rendezzük. A vezérlő rétegben két függvényt írunk, amely a modell rétegtől jut hozzá az adatokat tartalmazó generikus listához – átvett paraméterként –, és a visszaadott érték a nézet réteghez kerül.
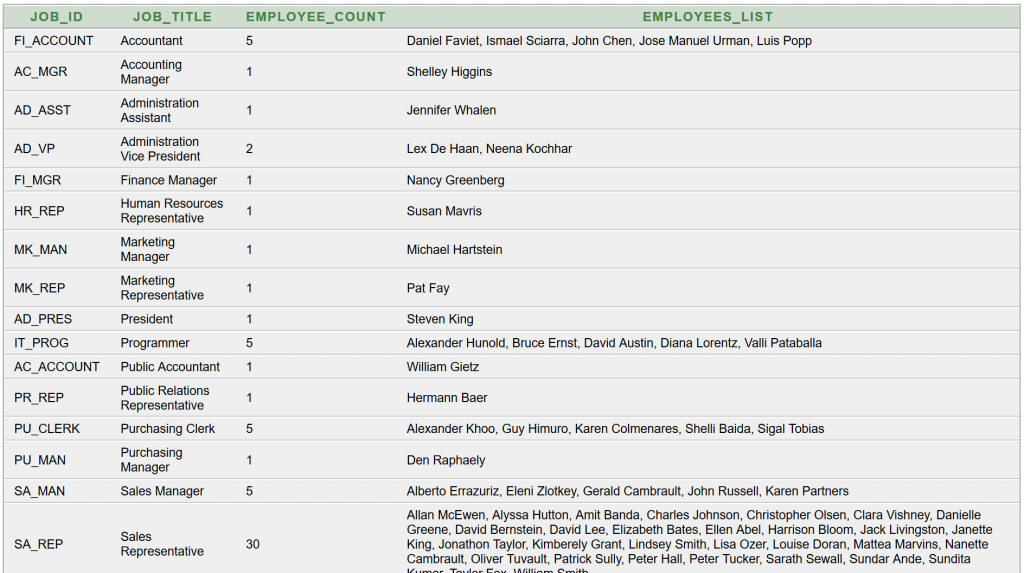
A csoportváltás algoritmust használjuk, amely 5 blokkból épül fel. A külső ciklus előtti 1. blokk és utáni 5. blokk egyszer hajtódik végre, az előkészítő és lezáró tevékenységek tartoznak ide. A külső ciklus elején és végén található 2. és 4. blokk a belső cikluson kívül fut le, csoportonként, kategóriánként, részlegenként egyszer (most összesen 11-szer mindkettő). A 3. blokk a belső cikluson belül található, és alkalmazottanként egyszer hajtódik végre (most összesen 106-szor).
Háromszintű fát építünk: a gyökérbe (0. szint) fix, beégetett szövegként kerül a cég neve és a teljes létszám. Az 1. szinten jelennek meg a részlegek nevei és a hozzájuk tartozó létszámok. A 2. szint az alkalmazottak neveiből áll.
1. megoldás
A megoldás
faKeszit1() függvénye szöveges adatot eredményez. Ez jól használható teszteléshez: megvan-e az összes adat, megfelelő-e a részlegek sorrendje azon belül az alkalmazottak sorrendje, működik-e a csoportosítás, rendben van-e a megszámolás?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
public String faKeszit1(ArrayList lista) { //1 StringBuilder faGyoker= new StringBuilder("Cég ("+lista.size()+" fő)"); int i=0; while(i<lista.size()) { //2 String aktReszleg=lista.get(i).getReszleg(); ArrayList faReszlegAlkalmazott=new ArrayList<>(); while(i<lista.size() && lista.get(i).getReszleg().equals(aktReszleg)) { //3 faReszlegAlkalmazott.add(lista.get(i).getNev()); i++; } //4 String faReszleg="\n "+aktReszleg+ " ("+faReszlegAlkalmazott.size()+" fő)\n "; faGyoker.append(faReszleg+" "+ String.join("\n ",faReszlegAlkalmazott)); } //5 return faGyoker.toString(); } |
A
faKeszit1() függvény egy sok lépésben összefűzött (konkatenált) szöveget ad vissza. Az 1. blokkban előkészítjük a fa gyökerét, ami
StringBuilder típusú, hiszen sokszor manipuláljuk és inicializáljuk a lista indexelésére használt
i ciklusváltozót. A 2. blokkban megjegyezzük az aktuális részleget és előkészítjük az ehhez tartozó alkalmazottak nevét tároló generikus listát (
faReszlegAlkalmazott). Az
aktReszleg-hez tartozó alkalmazottak neveit összegyűjtjük a 3. blokkban. Egy részleg feldolgozását a 4. blokkban fejezzük be a fa aktuális 1. és 2. szinten lévő elemeinek szövegbe való beszúrásával. A belső ciklushoz kötődően megszámolást nem kell alkalmaznunk, hiszen az adott részlegben dolgozó alkalmazottak száma a generikus listától elkérhető (
size()). Építünk arra, hogy a külső ciklusból nézve az egymás után végrehajtódó 2. és 4. blokkban az
aktReszleg nem változik meg. A 2. blokkban még nem tudjuk a fa aktuális 1. szintjét hozzáfűzni a szöveghez, hiszen a létszám csak a belső ciklusban felépülő kollekciótól kérhető el utólag. Szükséges némi késleltetés, hiszen a szöveg összefűzése és lényegesen egyszerűbb (mint utólag manipulálni megfelelő helyeken). Az 5. blokkban a csoportváltás algoritmushoz kötődő tevékenységünk nincs.
Az 1. megoldás eredménye
|
|
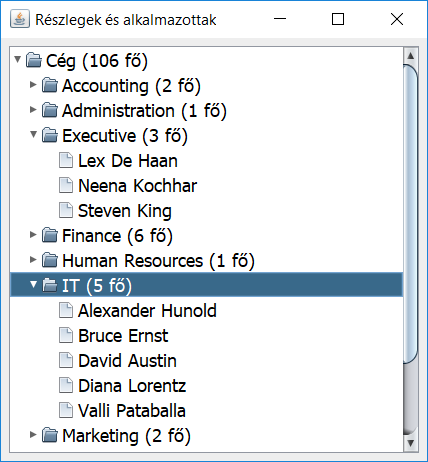
Cég (106 fő) Accounting (2 fő) Shelley Higgins William Gietz Administration (1 fő) Jennifer Whalen Executive (3 fő) Lex De Haan Neena Kochhar Steven King ... |
2. megoldás
A
faKeszit2() függvénynél alkalmazkodunk ahhoz, hogy a
JTree vizuális komponenshez
DefaultTreeModel observable típusú modell szükséges, így ezzel térünk vissza (
faModell). A fa csomópontjai
DefaultMutableTreeNode osztályú objektumok lesznek, amelyeknek a
userObject tulajdonsága szükség esetén manipulálható. Az 1 blokkban beszúrjuk a fa gyökerét (
faGyoker), amihez a későbbiekben csatlakozik a fa többi eleme. A 2. blokkban megjegyezzük az aktuális részleget és előkészítjük – megjelenítendő szöveg nélkül – a
faReszleg csomópontot. A 3. blokkban fabeli csomópontként a fa 1. szintjén megjelenő részleghez névtelenül hozzáadjuk a fa 2. szintjére kerülő – aktuális részleghez tartozó – alkalmazottak nevét. A 4. blokkban utólag módosítjuk a
faReszleg csomópont megjelenítendő szövegét. Az aktuális részleg létszámát itt sem kell külön megszámolni, mert a
faReszleg-től elkérhető (
getChildCount()). Az 5. blokkban itt sincs különösebb teendőnk.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
public DefaultTreeModel faKeszit2(ArrayList<Alkalmazott> lista) { //1 DefaultMutableTreeNode faGyoker= new DefaultMutableTreeNode("Cég ("+lista.size()+" fő)"); DefaultTreeModel faModell=new DefaultTreeModel(faGyoker); int i=0; while(i<lista.size()) { //2 String aktReszleg=lista.get(i).getReszleg(); DefaultMutableTreeNode faReszleg=new DefaultMutableTreeNode(); while(i<lista.size() && lista.get(i).getReszleg().equals(aktReszleg)) { //3 faReszleg.add(new DefaultMutableTreeNode(lista.get(i).getNev())); i++; } //4 faReszleg.setUserObject( aktReszleg+" ("+faReszleg.getChildCount()+" fő)"); faGyoker.add(faReszleg); } //5 return faModell; } |
A 2. megoldás eredménye
A bejegyzéshez tartozó teljes forráskódot ILIAS e-learning tananyagban tesszük elérhetővé tanfolyamaink résztvevői számára.
Attól függően, hogyan jutunk hozzá a megjelenítéshez szükséges adatokhoz, több tanfolyamunkhoz is kapcsolódik a feladat és a modell rétegben mindig másképpen tervezünk és implementálunk:
- A Java SE szoftverfejlesztő tanfolyam 45-48. óra: Adatbázis-kezelés JDBC alapon, 1. rész alkalmán hagyományos SQL lekérdező utasítást készítünk JDBC környezetben.
- A Java EE szoftverfejlesztő tanfolyam 25-32. óra: Adatbázis-kezelés JPA alapon alkalommal a perzisztencia szolgáltatásait vetjük be.
- A Java adatbázis-kezelő tanfolyam 13-16. óra: Konzolos kliensalkalmazás fejlesztése JDBC alapon, 1. rész, 33-36. óra: Grafikus kliensalkalmazás fejlesztése JDBC alapon, 2. rész alkalmain hierarchikus lekérdezéseket használunk.

 Doktoranduszok programoznak – újratöltve
Doktoranduszok programoznak – újratöltve





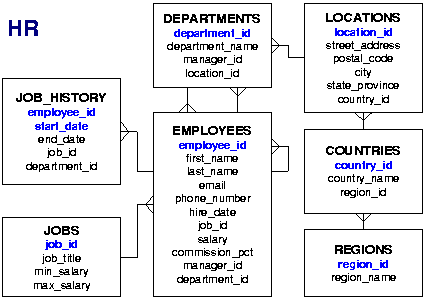
 Az SQL lekérdezések újabb típusát adják a hierarchikus lekérdezések. Az Oracle adatbázis-szerver már régóta támogatja ezt a lehetőséget. A hierarchia legtöbbször valamilyen fa adatszerkezethez kötődik. Ezek természetesen nem közvetlenül tárolódnak egy normalizált, relációs adatbázisban, de az adatok közötti kapcsolat értelmezése során felépíthető rekurzív módon a fa struktúra.
Az SQL lekérdezések újabb típusát adják a hierarchikus lekérdezések. Az Oracle adatbázis-szerver már régóta támogatja ezt a lehetőséget. A hierarchia legtöbbször valamilyen fa adatszerkezethez kötődik. Ezek természetesen nem közvetlenül tárolódnak egy normalizált, relációs adatbázisban, de az adatok közötti kapcsolat értelmezése során felépíthető rekurzív módon a fa struktúra.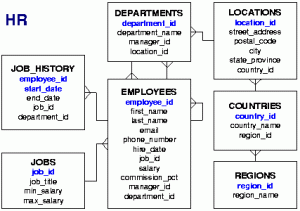
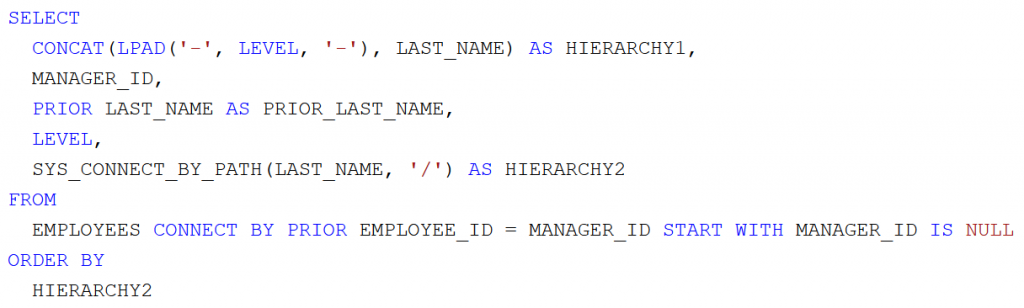
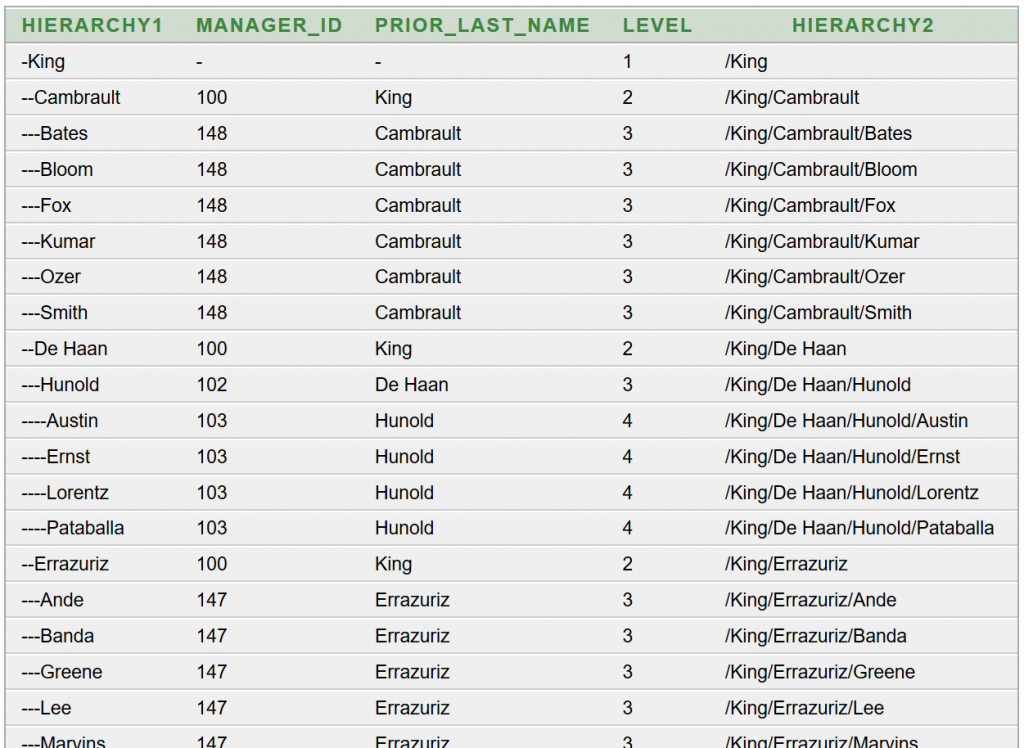

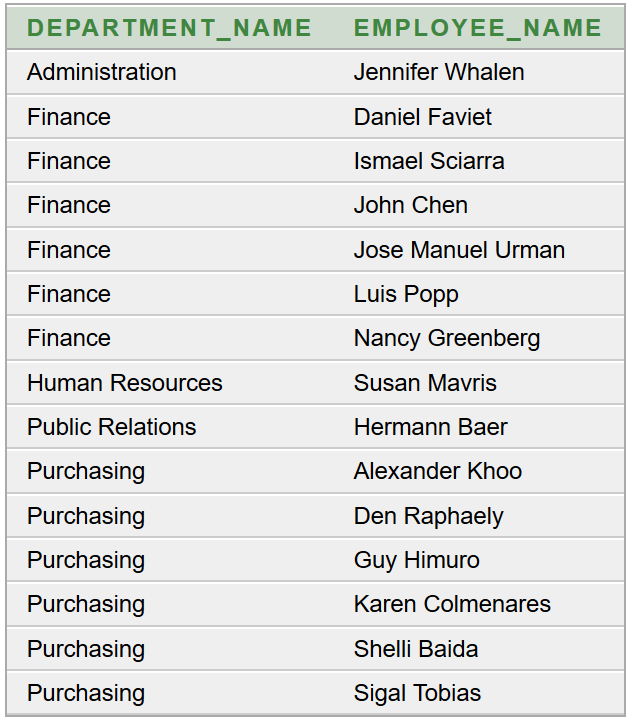

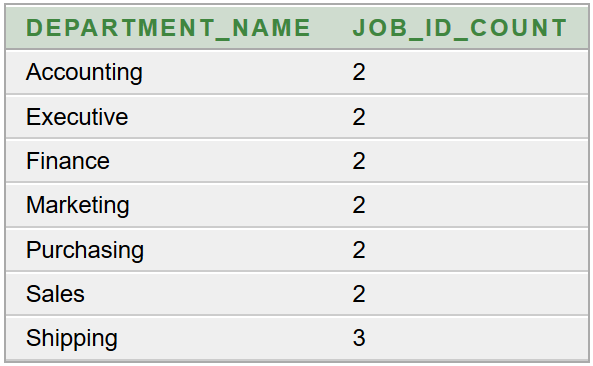
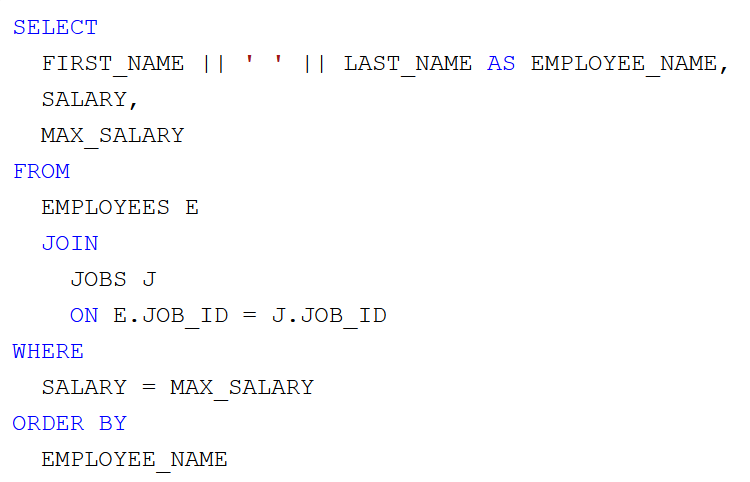

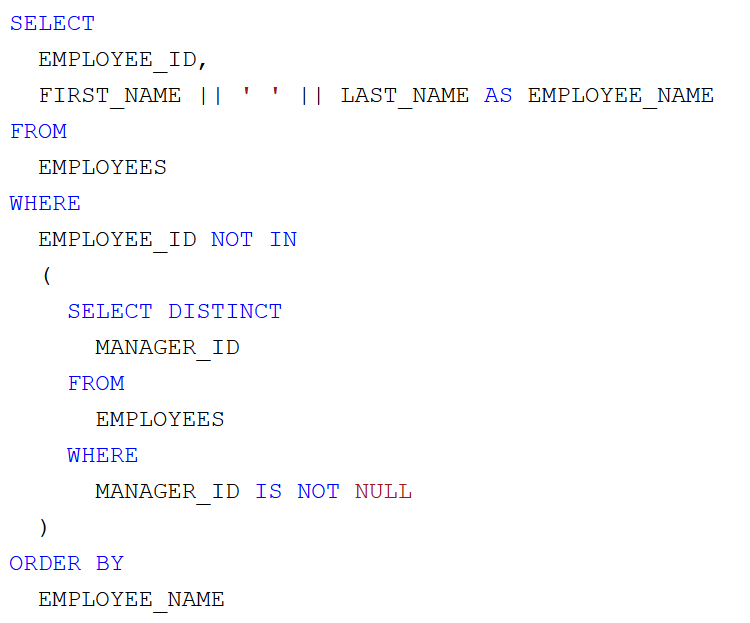
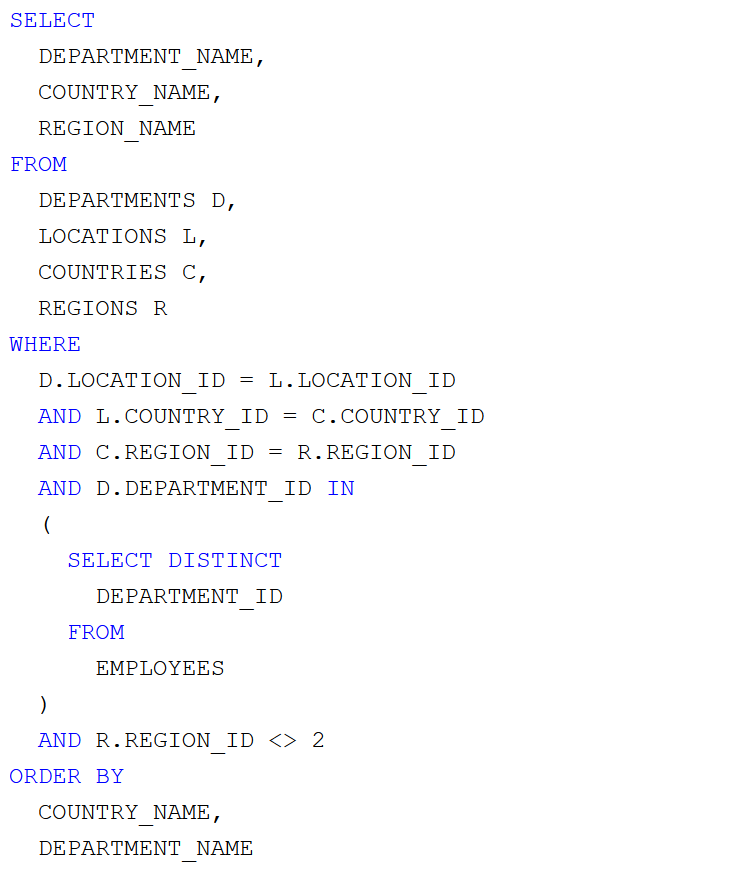
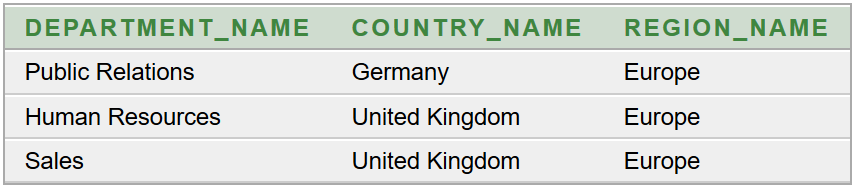
 Az a feladatunk, hogy az Oracle HR sémából lekérdezve állítsuk elő munkakörönként csoportosítva az alkalmazottak létszámát és névsorát. Adott a
Az a feladatunk, hogy az Oracle HR sémából lekérdezve állítsuk elő munkakörönként csoportosítva az alkalmazottak létszámát és névsorát. Adott a