
Címke: 2020
24 blog bejegyzésnél szerepel:
![]() Programozási Hét 2020 – CodeWeek.eu
Programozási Hét 2020 – CodeWeek.eu
![]() LEGO Education módszertani képzés / Robotika Mindstorms EV3 robottal
LEGO Education módszertani képzés / Robotika Mindstorms EV3 robottal


![]() Doktori értekezések védése a Miskolci Egyetemen
Doktori értekezések védése a Miskolci Egyetemen
 Céline Dion - Courage World Tour
Céline Dion - Courage World Tour
![]() Top 5 fizetésű alkalmazottak listája
Top 5 fizetésű alkalmazottak listája
![]() Egy matematika érettségi feladat megoldása programozással 2020
Egy matematika érettségi feladat megoldása programozással 2020
 Dr. Sheldon Cooper szólánc játéka
Dr. Sheldon Cooper szólánc játéka

![]() HWSW – Appmenedzsment és marketing meetup
HWSW – Appmenedzsment és marketing meetup


142 db hozzá kapcsolódó címke:
ADA konferencia (2), adatbázis (25), Agymenők (3), algoritmus (31), alkalmazottak fizetése (4), állásinterjú (10), álláskeresés (17), animáció (17), ASCII (6), becslés (6), címkefelhő (2), CodeWeek.eu (7), csoportmunka (10), csoportváltás (6), dátumkezelés (10), DE (3), Debreceni Egyetem (3), Digitális Témahét (8), doktori értekezés (2), doktori képzés (4), DUE (2), Dunaújvárosi Egyetem (2), életrajz (4), élményalapú tanulás (21), előadás műhely-napon (24), elosztott alkalmazás (14), EMT SzámOkt (4), EMT (4), Erdélyi Magyar Műszaki Tudományos Társaság (4), eredménytábla (10), érettségi feladat (8), értékelési szempont (6), érzékelés (3), évforduló (24), fájlkezelés (29), fejtörő (11), felvételi feladat (4), Fibonacci (3), film (1), fizika (7), funkcionális programozás (18), gamifikáció (33), Google Charts (5), Google Cloud Platform (2), grafika (26), grafikus felhasználói felület (40), hálózatkezelés (14), hatékonyság (28), hexadecimális (2), humor (4), HWSW (4), idézet (10), időjárás (2), ingyenes esemény (34), játék (9), Java forráskód (63), JExcel API (4), JSON (4), JSP (3), kivételkezelés (13), kliensprogram (13), kódolás/dekódolás (6), kollekció (32), konferencia (15), KSH (3), Kutatók éjszakája (8), lambda kifejezés (13), LEGO (3), lekérdezés (18), lépésszám (9), logikai feladat (21), logisztika (5), lottószelvény (10), marsjáró (1), matematika érettségi feladat (8), matematika (30), ME (1), megemlékezés (2), mém (7), Mentőexpedíció (1), mesterséges intelligencia (12), metódus (30), Miskolci Egyetem (1), MMO (6), mobil robot (2), Multimédia az oktatásban konferencia (6), MVC (12), naptár (26), NASA (2), nekrológ (1), népesedési világnap (1), Neumann János Számítógép-tudományi Társaság (8), NJSZT Multimédia az oktatásban (6), NJSZT (8), nyilvános védés (1), objektumorientált programozás (85), operációs rendszerek (2), Oracle HR séma (12), orientáló modul (39), öröklődés (16), pályaorientáció (28), programozás (106), Programozási Hét (7), programozási tételek (28), projektmunka (5), protokoll (számítógép-hálózat) (3), publikáció (9), rajzolás (15), rejtjelezés (3), rekurzió (9), rendezvény 2020 (12), robot verseny (2), robotika (12), robotprogramozás (11), SQL forráskód (12), statisztika (11), STEM (3), Stream API (14), swing (26), szakmai előadás (31), szakmai modul (96), Számítástechnika és Oktatás Konferencia (4), SzámOkt (4), szófelhő (2), táblázat (11), távbeszélő készülék (2), térinformatika (4), tervezés (41), tévésorozat (3), titkosítás/visszafejtés (4), többféle megoldás összehasonlítása (37), tömb (17), toplista (5), továbbfejlesztés (23), továbbképzés (4), transzformáció (8), ünnepnap (13), videó (5), WITSEC (1), Women in IT Security (1), worldometer (2), XML (8)


 Dr. Sheldon Cooper karakterét nem kell bemutatni. Az Agymenők (The Big Bang Theory) című sorozat 2. évad 5. epizódjának címe A vitatkozás nagymestere (The Euclid Alternative). Nagyon találó az epizód címe magyarul. Miközben Penny reggel Sheldont munkába viszi, Sheldon az autóban kémiai elemek nevéből álló szólánc játékával különösen Penny agyára megy (pedig a játékot Penny nyeri ?):
Dr. Sheldon Cooper karakterét nem kell bemutatni. Az Agymenők (The Big Bang Theory) című sorozat 2. évad 5. epizódjának címe A vitatkozás nagymestere (The Euclid Alternative). Nagyon találó az epizód címe magyarul. Miközben Penny reggel Sheldont munkába viszi, Sheldon az autóban kémiai elemek nevéből álló szólánc játékával különösen Penny agyára megy (pedig a játékot Penny nyeri ?):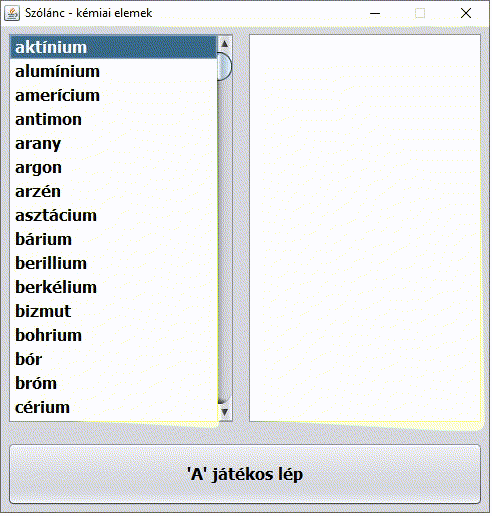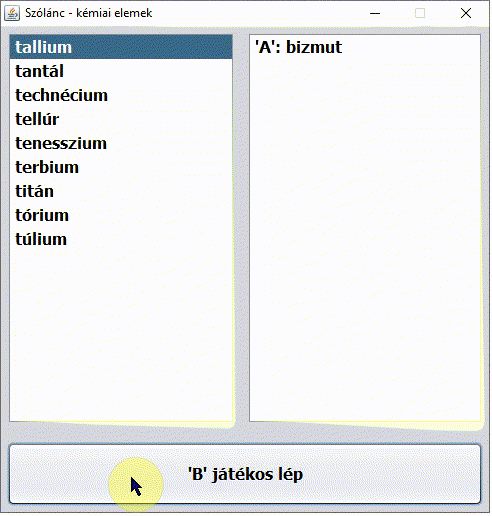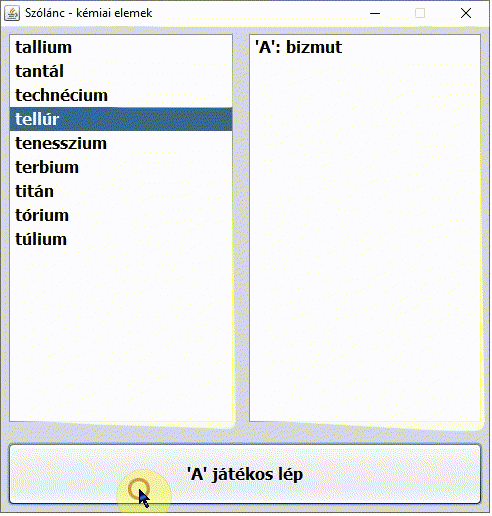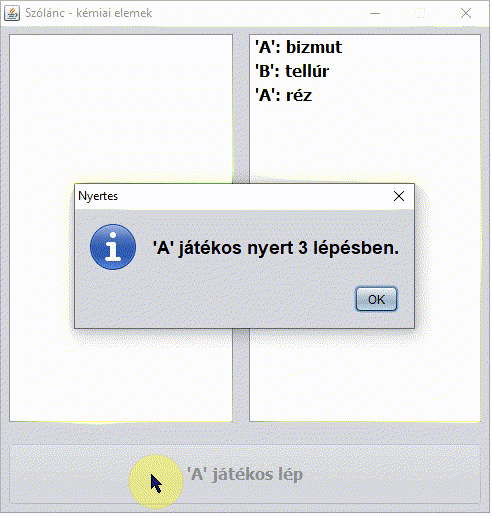
 A
A 



