Címke: továbbfejlesztés
23 blog bejegyzésnél szerepel:

 Kép élesítése effektus működése
Kép élesítése effektus működése
 Beszámoló: it-tanfolyam.hu STEM nyári tábor 2023
Beszámoló: it-tanfolyam.hu STEM nyári tábor 2023
![]() Alkalmazottak életpálya modellje – mi lenne, ha…?
Alkalmazottak életpálya modellje – mi lenne, ha…?
![]() Naprendszer szimuláció – megvalósítás Java nyelven
Naprendszer szimuláció – megvalósítás Java nyelven
![]() Naprendszer szimuláció – objektumorientált tervezés
Naprendszer szimuláció – objektumorientált tervezés
![]() Naprendszer szimuláció – elméleti háttér
Naprendszer szimuláció – elméleti háttér
![]() Egy matematika érettségi feladat megoldása programozással 2022
Egy matematika érettségi feladat megoldása programozással 2022
 Programozás Java nyelven könyv - új, 2022-es kiadás
Programozás Java nyelven könyv - új, 2022-es kiadás



162 db hozzá kapcsolódó címke:
2017 (24), 2018 (24), 2019 (24), 2020 (24), 2021 (24), 2022 (24), 2023 (24), 2024 (8), adatbázis (25), Agymenők (3), algoritmus (31), alkalmazottak életpálya modellje (3), alkalmazottak fizetése (4), alkalmazottak munkaköre (6), állásinterjú (10), álláskeresés (17), animáció (17), AnyChart (1), ASCII (6), atipikus megoldás (5), becslés (6), brute force (7), ChatGPT (1), ciklusok (18), címkefelhő (2), csoportmunka (10), csoportváltás (6), dátumkezelés (10), DUF (3), Dunaújvárosi Főiskola (3), életpálya modell (3), élményalapú tanulás (21), előadás műhely-napon (24), elosztott alkalmazás (14), eredménytábla (10), érettségi feladat (8), évforduló (24), fájlkezelés (29), fejtörő (11), fizika (7), funkcionális programozás (18), gamifikáció (33), GitHub (2), Google Charts (5), Google Cloud Platform (2), grafika (26), grafikus felhasználói felület (40), hálózatkezelés (14), hatékonyság (28), humor (4), időzítő (4), IEEE Spectrum (2), Indeed (2), ingyenes esemény (34), ipar 4.0 (6), ipar 5.0 (2), játék (9), Java forráskód (63), JavaFX (3), JavaScript (6), JDBC (12), JExcel API (4), JSON (4), JSP (3), karrier (17), karrierváltás (14), képeffektus (1), keresztrejtvény (2), kígyókocka (2), kivételkezelés (13), kliens-szerver (7), kliensprogram (13), kódolás/dekódolás (6), kollekció (32), kombinatorika (7), könyvajánló (4), közelítés (3), kriptoaritmetika (2), KSH (3), Kutatók éjszakája (8), lambda kifejezés (13), LEGO (3), lekérdezés (18), lépésszám (9), logikai feladat (21), logisztika (5), lottószelvény (10), matematika érettségi feladat (8), matematika (30), mém (7), memória használat (3), mesterséges intelligencia (12), metódus (30), munkaerőpiac (14), MVC (12), Naprendszer (5), naptár (26), NASA (2), népesedési világnap (1), nyári tábor (2), OKJ szakképzés (3), okos gyár (5), objektumorientált programozás (85), OpenWeatherMap (2), optikai csalódás (2), Oracle HR séma (12), orientáló modul (39), öröklődés (16), összefoglalás (2), osztálydiagram (7), pályaorientáció (28), pályázat (6), PDF (1), ProgCont API (3), programozás (106), programozási tételek (28), projektmunka (5), protokoll (számítógép-hálózat) (3), PYPL (2), Python (4), rajzolás (15), Reddit (2), rekurzió (9), rendezvény 2023 (10), RMI (3), robotika (12), robotprogramozás (11), soft skill (10), SQL forráskód (12), Stack Overflow (2), statisztika (11), STEM (3), Stream API (14), swing (26), szakmai előadás (31), szakmai modul (96), szálkezelés (4), szimuláció (10), szófelhő (2), sztereogram (1), táblázat (11), tananyagfejlesztés (8), térinformatika (4), tervezés (41), tesztelés (21), tévésorozat (3), TIOBE (2), tipikus munkanap (6), többféle megoldás összehasonlítása (37), tömb (17), tömegvonzás (5), toplista (5), transzformáció (8), Trendy Skills (2), UML (8), ünnepnap (13), vélemény (4), videó (5), virtuális valóság (5), visszajelzés (5), worldometer (2), XML (8)

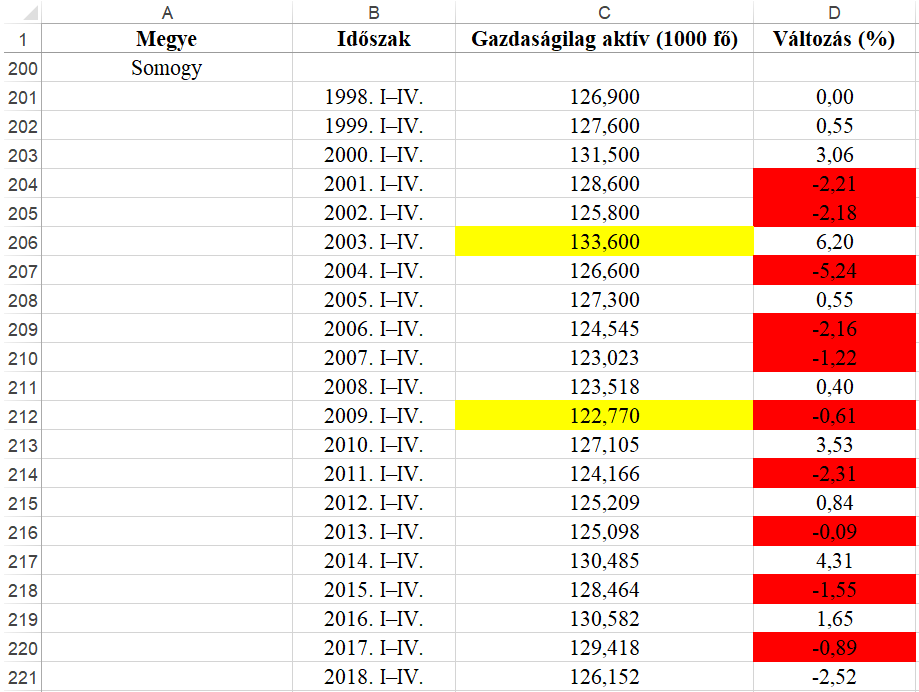
 Vajon hogyan kerül elő a Rómeó és Júlia az
Vajon hogyan kerül elő a Rómeó és Júlia az 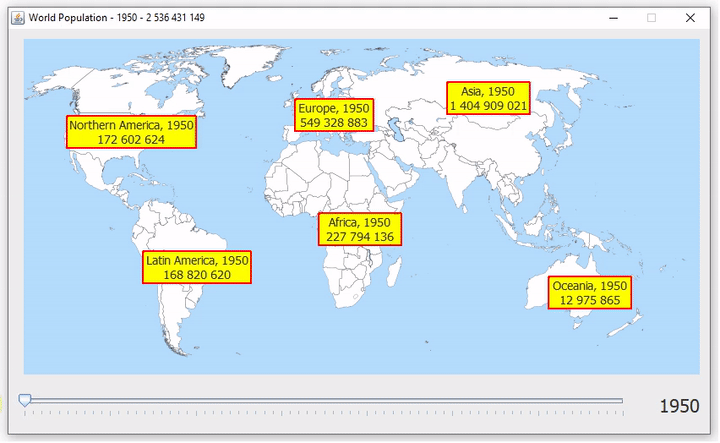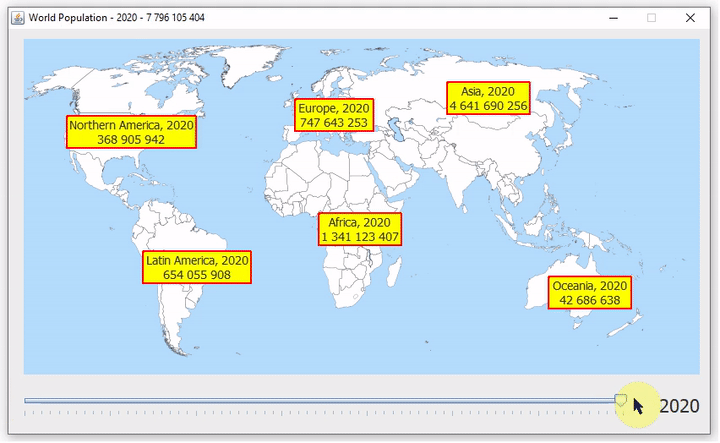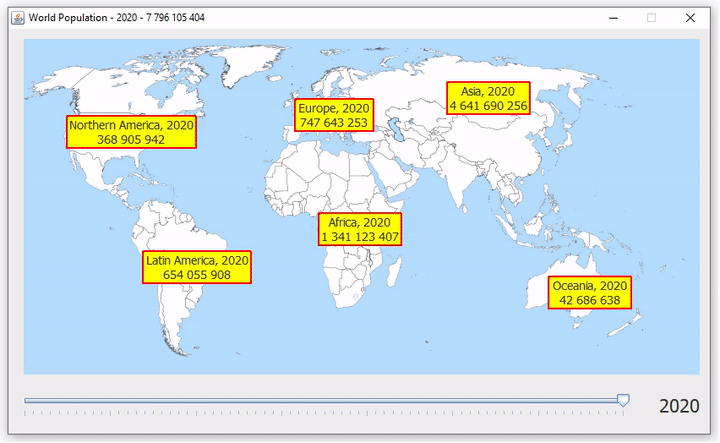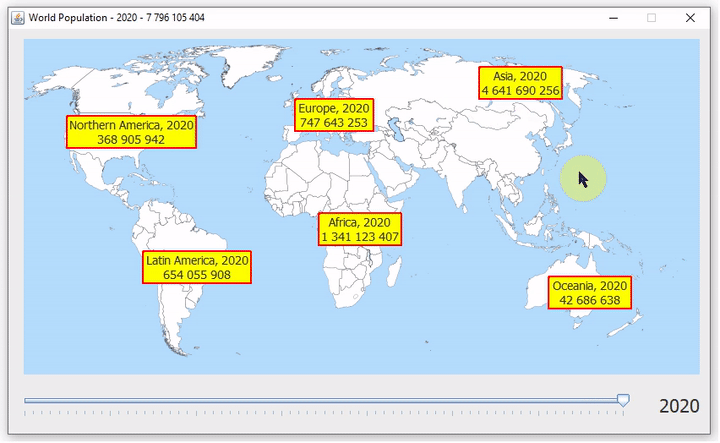
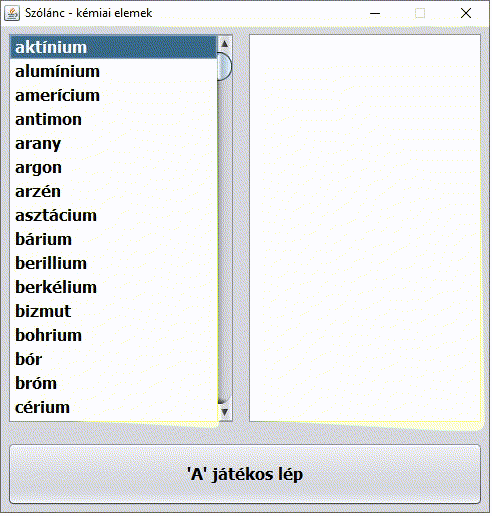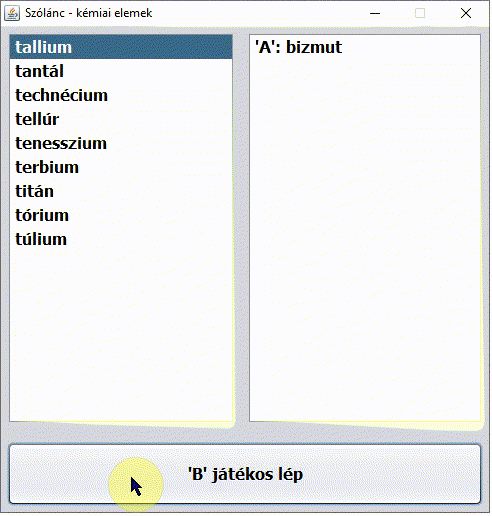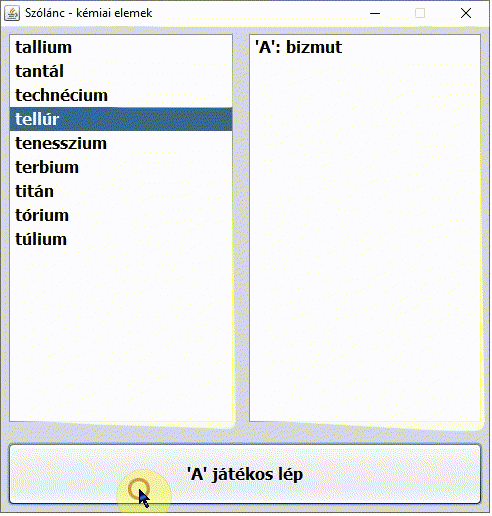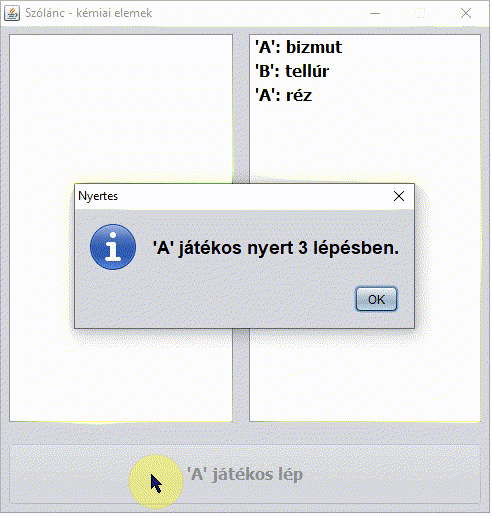
 Dr. Sheldon Cooper karakterét nem kell bemutatni. Az Agymenők (The Big Bang Theory) című sorozat 2. évad 5. epizódjának címe A vitatkozás nagymestere (The Euclid Alternative). Nagyon találó az epizód címe magyarul. Miközben Penny reggel Sheldont munkába viszi, Sheldon az autóban kémiai elemek nevéből álló szólánc játékával különösen Penny agyára megy (pedig a játékot Penny nyeri ?):
Dr. Sheldon Cooper karakterét nem kell bemutatni. Az Agymenők (The Big Bang Theory) című sorozat 2. évad 5. epizódjának címe A vitatkozás nagymestere (The Euclid Alternative). Nagyon találó az epizód címe magyarul. Miközben Penny reggel Sheldont munkába viszi, Sheldon az autóban kémiai elemek nevéből álló szólánc játékával különösen Penny agyára megy (pedig a játékot Penny nyeri ?):