
Címke: programozás
106 blog bejegyzésnél szerepel:

 Dr. Sheldon Cooper kő-papír-olló-gyík-Spock játéka
Dr. Sheldon Cooper kő-papír-olló-gyík-Spock játéka


 Doktoranduszok programoznak – újratöltve
Doktoranduszok programoznak – újratöltve
![]() Kölcsönös ajándékozás véletlenszerűen
Kölcsönös ajándékozás véletlenszerűen
 Kép élesítése effektus működése
Kép élesítése effektus működése
![]() Programozási Hét 2023 – CodeWeek.eu
Programozási Hét 2023 – CodeWeek.eu
 Java program memória használatának mérése
Java program memória használatának mérése
 Beszámoló: it-tanfolyam.hu STEM nyári tábor 2023
Beszámoló: it-tanfolyam.hu STEM nyári tábor 2023
![]() Alkalmazottak életpálya modellje – mi lenne, ha…?
Alkalmazottak életpálya modellje – mi lenne, ha…?
![]() Alkalmazottak életpálya modellje – munkakör, fizetés, jutalék
Alkalmazottak életpálya modellje – munkakör, fizetés, jutalék
![]() Egy matematika érettségi feladat megoldása programozással 2023
Egy matematika érettségi feladat megoldása programozással 2023
![]() Naprendszer szimuláció – megvalósítás Java nyelven
Naprendszer szimuláció – megvalósítás Java nyelven
![]() Naprendszer szimuláció – objektumorientált tervezés
Naprendszer szimuláció – objektumorientált tervezés
![]() Naprendszer szimuláció – elméleti háttér
Naprendszer szimuláció – elméleti háttér
![]() Tankocka – Legyen Ön is milliomos! – Programozás Java nyelven
Tankocka – Legyen Ön is milliomos! – Programozás Java nyelven
![]() Tankocka – Csoportba rendezés: adatbázis-kezelés, fájlkezelés, hálózatkezelés
Tankocka – Csoportba rendezés: adatbázis-kezelés, fájlkezelés, hálózatkezelés
![]() Tankocka – Rövid válasz: Java konstansok
Tankocka – Rövid válasz: Java konstansok
![]() Programozási Hét 2022 – CodeWeek.eu
Programozási Hét 2022 – CodeWeek.eu
![]() Tankocka – Szókereső: rendezési algoritmusok
Tankocka – Szókereső: rendezési algoritmusok
![]() Tankocka – Keresztrejtvény: programozási tételek
Tankocka – Keresztrejtvény: programozási tételek
![]() Tankocka – Egyszerű sorbarendezés: Java forráskód
Tankocka – Egyszerű sorbarendezés: Java forráskód
![]() Tankocka – Párkereső: csomag, osztály, interfész
Tankocka – Párkereső: csomag, osztály, interfész
![]() Egy matematika érettségi feladat megoldása programozással 2022
Egy matematika érettségi feladat megoldása programozással 2022
![]() Tankocka – Hiányos szöveg: objektumorientált programozás
Tankocka – Hiányos szöveg: objektumorientált programozás
![]() Tankocka – Idővonal: Java verziók újdonságai
Tankocka – Idővonal: Java verziók újdonságai
 Programozás Java nyelven könyv - új, 2022-es kiadás
Programozás Java nyelven könyv - új, 2022-es kiadás
![]() Tankocka – Hozzárendeléses táblázat: Java kollekciók
Tankocka – Hozzárendeléses táblázat: Java kollekciók
![]() Egy példányban futó Java program
Egy példányban futó Java program
![]() Tankocka – Párosítós játék: Programozás Java nyelven
Tankocka – Párosítós játék: Programozás Java nyelven
![]() Táblázatos komponens testreszabása
Táblázatos komponens testreszabása
![]() Kik vettek részt projektmunkában?
Kik vettek részt projektmunkában?
![]() Egy matematika érettségi feladat megoldása programozással 2021
Egy matematika érettségi feladat megoldása programozással 2021


![]() LEGO Education módszertani képzés / Robotika Mindstorms EV3 robottal
LEGO Education módszertani képzés / Robotika Mindstorms EV3 robottal
 Céline Dion - Courage World Tour
Céline Dion - Courage World Tour
![]() Egy matematika érettségi feladat megoldása programozással 2020
Egy matematika érettségi feladat megoldása programozással 2020
![]() Programozási nyelvek népszerűsége
Programozási nyelvek népszerűsége
![]() Egy matematika érettségi feladat megoldása programozással 2019
Egy matematika érettségi feladat megoldása programozással 2019

 Stream API lambda kifejezésekkel
Stream API lambda kifejezésekkel


![]() Egy matematika érettségi feladat megoldása programozással 2018
Egy matematika érettségi feladat megoldása programozással 2018



 Telefonos billentyűzettel kódolunk/dekódolunk
Telefonos billentyűzettel kódolunk/dekódolunk
 Gyűjtsünk össze adatokat névjegykártya készítéshez!
Gyűjtsünk össze adatokat névjegykártya készítéshez!





Ismerkedjünk lambda kifejezésekkel!


![]() Egy matematika érettségi feladat megoldása programozással 2017
Egy matematika érettségi feladat megoldása programozással 2017



234 db hozzá kapcsolódó címke:
2017 (24), 2018 (24), 2019 (24), 2020 (24), 2021 (24), 2022 (24), 2023 (24), 2024 (8), ADA konferencia (2), adatbázis (25), Agymenők (3), algoritmus (31), alkalmazottak életpálya modellje (3), alkalmazottak fizetése (4), alkalmazottak munkaköre (6), állásinterjú (10), álláskeresés (17), Android (4), animáció (17), AnyChart (1), Applet (1), ASCII (6), atipikus megoldás (5), becslés (6), brute force (7), C# forráskód (2), ChatGPT (1), ciklusok (18), címkefelhő (2), CodeWeek.eu (7), csoportmunka (10), csoportváltás (6), dátumkezelés (10), DE (3), Debreceni Egyetem (3), digitális élményközpont (3), Digitális Témahét (8), doktori képzés (4), DUE (2), DUF (3), Dunaújvárosi Egyetem (2), Dunaújvárosi Főiskola (3), életpálya modell (3), életrajz (4), élményalapú tanulás (21), előadás műhely-napon (24), elosztott alkalmazás (14), eredménytábla (10), érettségi feladat (8), értékelési szempont (6), érzékelés (3), euklideszi algoritmus (1), Euler (3), évforduló (24), fájlkezelés (29), fejtörő (11), felvételi feladat (4), Fibonacci (3), fizika (7), fotópályázat (1), fraktál (1), funkcionális programozás (18), gamifikáció (33), GitHub (2), Google Charts (5), Google Cloud Platform (2), Google Trends (1), grafika (26), grafikus felhasználói felület (40), hálózatkezelés (14), hatékonyság (28), hexadecimális (2), hierarchikus lekérdezés (7), humor (4), húsvétvasárnap (1), idézet (10), időjárás (2), időzítő (4), IEEE Spectrum (2), Indeed (2), infotanulmány (1), ingyenes esemény (34), ipar 4.0 (6), ipar 5.0 (2), IT történet (20), játék (9), Java forráskód (63), Java verziók (4), JavaFX (3), JavaScript (6), JDBC (12), JExcel API (4), JFreeChart (7), JSON (4), JSP (3), JTable (7), JTree (6), kapitány (3), karrier (17), karrierváltás (14), képeffektus (1), keresztrejtvény (2), kígyókocka (2), kivételkezelés (13), kliens-szerver (7), kliensprogram (13), Koch-görbe (1), kockadobás (1), kódolás/dekódolás (6), kollekció (32), kombinatorika (7), konferencia (15), könyvajánló (4), közelítés (3), kriptoaritmetika (2), KSH (3), Kutatók éjszakája (8), lambda kifejezés (13), leghosszabb közös részsorozat (1), legnagyobb közös osztó (1), LEGO (3), lekérdezés (18), lépésszám (9), logikai feladat (21), logisztika (5), lottószelvény (10), MAFIOK (1), matematika érettségi feladat (8), matematika (30), megemlékezés (2), mém (7), memória használat (3), mesterséges intelligencia (12), metódus (30), MMO (6), Multimédia az oktatásban konferencia (6), munkaerőpiac (14), munkahelyi elvárás (5), MVC (12), Naprendszer (5), naptár (26), NASA (2), Nemzeti Közszolgálati Egyetem (2), népesedési világnap (1), Neumann János Számítógép-tudományi Társaság (8), NJSZT Multimédia az oktatásban (6), NJSZT (8), NKE (2), nőnap (1), nyári tábor (2), OKJ szakképzés (3), okos gyár (5), objektumorientált programozás (85), OpenWeatherMap (2), operációs rendszerek (2), optikai csalódás (2), Oracle HR séma (12), organogram (2), orientáló modul (39), öröklődés (16), összefoglalás (2), osztálydiagram (7), pályaorientáció (28), pályázat (6), PDF (1), Pi nap (2), Pi (2), ProgCont API (3), Programozási Hét (7), programozási tételek (28), projektmunka (5), protokoll (számítógép-hálózat) (3), publikáció (9), PYPL (2), Python (4), rajzolás (15), Reddit (2), rejtjelezés (3), rekurzió (9), rendezvény 2017 (5), rendezvény 2018 (10), rendezvény 2019 (11), rendezvény 2020 (12), rendezvény 2021 (6), rendezvény 2022 (8), rendezvény 2023 (10), rendezvény 2024 (1), RMI (3), robotika (12), robotprogramozás (11), Servlet (1), soft skill (10), SQL forráskód (12), Stack Overflow (2), statisztika (11), STEM (3), Stream API (14), swing (26), szakmai előadás (31), szakmai modul (96), szálkezelés (4), szimuláció (10), szófelhő (2), sztereogram (1), táblázat (11), tananyagfejlesztés (8), tankocka (15), télapó probléma (1), térinformatika (4), tervezés (41), tesztelés (21), tévésorozat (3), TIOBE (2), tipikus munkanap (6), titkosítás/visszafejtés (4), többféle megoldás összehasonlítása (37), tömb (17), tömegvonzás (5), toplista (5), továbbfejlesztés (23), továbbképzés (4), transzformáció (8), Trendy Skills (2), UML (8), Unity (2), ünnepnap (13), vélemény (4), videó (5), virtuális múzeum (3), virtuális valóság (5), visszajelzés (5), Webby Giants (1), worldometer (2), XML (8)
 Nemrég egy betűket és számokat tartalmazó kódolt szöveget kaptam azzal a kéréssel, hogy próbáljam megfejteni. A titkosított szöveget a következő formátumban kaptam:
Nemrég egy betűket és számokat tartalmazó kódolt szöveget kaptam azzal a kéréssel, hogy próbáljam megfejteni. A titkosított szöveget a következő formátumban kaptam:
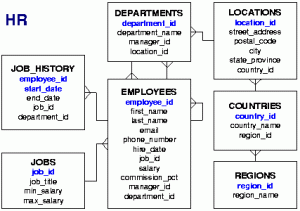

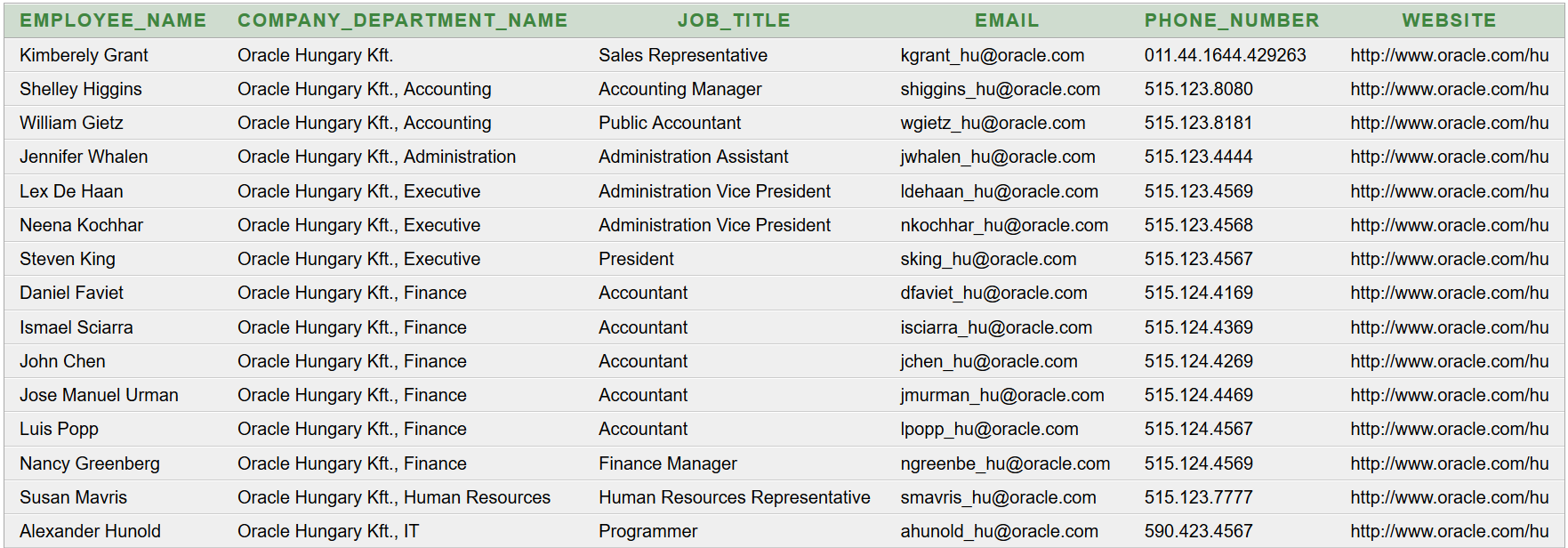
 Az adatok strukturális és könnyen értelmezhető formában való megjelenítése egy szoftver felhasználói felületén átgondolt tervezést igényel. Az adatokhoz hozzá kell jutni, ki kell választani a megfelelő grafikus komponenst, a mögötte lévő adatmodellt, össze kell ezeket kötni. Gyakran előforduló feladat, hogy táblázatosan is ábrázolható adatokból – felhasználva az adatok közötti összefüggéseket és kapcsolatokat – csoportosítva jelenítsünk meg hierarchikusan, fa struktúrában, kinyitható-becsukható formában, ahogyan ezt a felhasználók jól ismerik a fájl- és menürendszereket használva.
Az adatok strukturális és könnyen értelmezhető formában való megjelenítése egy szoftver felhasználói felületén átgondolt tervezést igényel. Az adatokhoz hozzá kell jutni, ki kell választani a megfelelő grafikus komponenst, a mögötte lévő adatmodellt, össze kell ezeket kötni. Gyakran előforduló feladat, hogy táblázatosan is ábrázolható adatokból – felhasználva az adatok közötti összefüggéseket és kapcsolatokat – csoportosítva jelenítsünk meg hierarchikusan, fa struktúrában, kinyitható-becsukható formában, ahogyan ezt a felhasználók jól ismerik a fájl- és menürendszereket használva.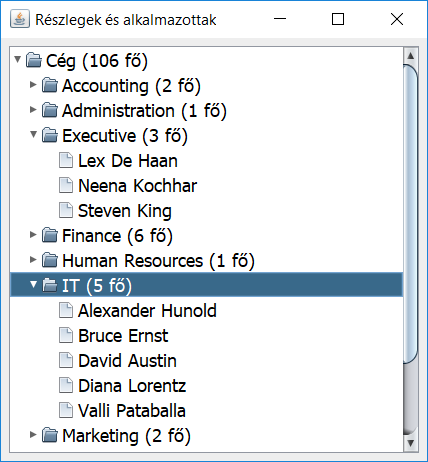
 Az operációs rendszerek tervezésének fontos része az ütemezési, erőforrás- és szálkezelési feladatok problémamentes, holtpontmentes megoldása, szinkronizálása, amiről sok ismert szerző publikált már, néhányan közülük angol nyelven:
Az operációs rendszerek tervezésének fontos része az ütemezési, erőforrás- és szálkezelési feladatok problémamentes, holtpontmentes megoldása, szinkronizálása, amiről sok ismert szerző publikált már, néhányan közülük angol nyelven: